前言
A Guide to the Kubernetes Networking Model 一文生动形象地介绍了 Kubernetes 中的网络模型,然而受篇幅所限,作者并没有对 Pod 跨节点通信时数据包在节点之间传递的细节进行过多讨论。
我们已经知道,Docker 使用端口映射的方式实现不同主机间容器的通信,Kubernetes 中同样也有 hostPort 的概念。但是当节点和 Pod 的数量上升后,手动管理节点上绑定的端口是十分困难的,这也是NodePort类型的 Service 的缺点之一。而一旦 Pod 不再“借用”节点的 IP 和端口来暴露自身的服务,就不得不面临一个棘手的问题:Pod 的本质是节点中的进程,节点外的物理网络设备(交换机/路由器)并不知晓 Pod 的存在。它们在接收目的地址为 Pod IP 的数据包时,无法完成进一步的传输工作。
为此我们需要使用一些 CNI(Container Network Interface)插件来完善 Kubernetes 集群的网络模型,这种新型的网络设计理念被称为 SDN(Software-defined Networking)。根据 SDN 实现的层级,我们可以将其分为 Underlay Network 和 Overlay Network:
Overlay 网络允许设备跨越底层物理网络(Underlay Network)进行通信,而底层却并不知晓 Overlay 网络的存在。Underlay 网络是专门用来承载用户 IP 流量的基础架构层,它与 Overlay 网络之间的关系有点类似物理机和虚拟机。Underlay 网络和物理机都是真正存在的实体,它们分别对应着真实存在的网络设备和计算设备,而 Overlay 网络和虚拟机都是依托在下层实体使用软件虚拟出来的层级。
Underlay Network
利用 Underlay Network 实现 Pod 跨节点通信,既可以只依赖 TCP/IP 模型中的二层协议,也可以使用三层。但无论哪种实现方式,都必须对底层的物理网络有所要求。
二层
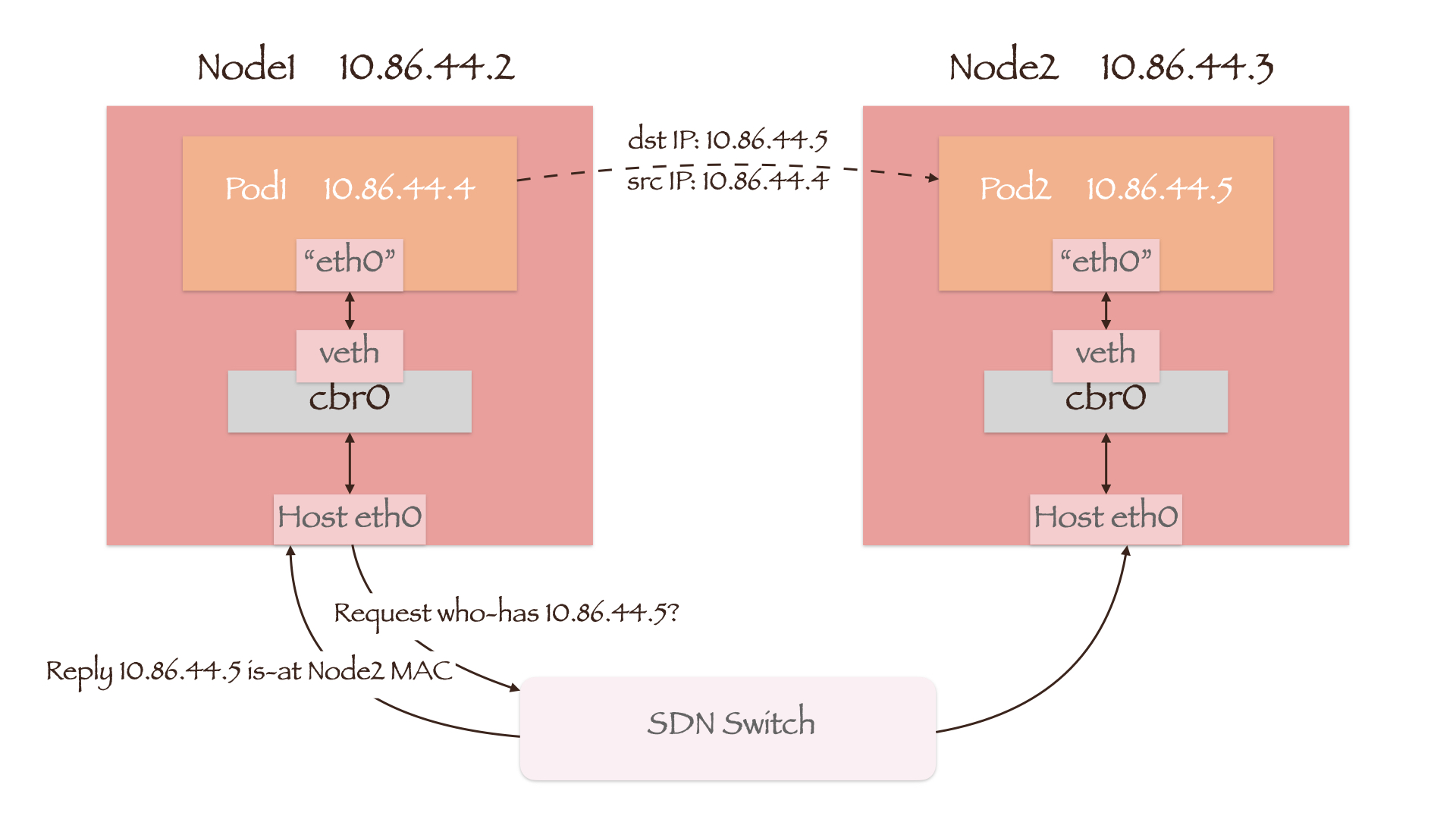
如图所示,Pod 与节点的 IP 地址均处于同一网段。当 Pod1 向另一节点上的 Pod2 发起通信时,数据包首先通过veth-pair和cbr0送往 Node1 的网卡。由于目的地址 10.86.44.4 与 Node1 同网段,因此 Node1 将通过 ARP 广播请求 10.86.44.4 的 MAC 地址。
CNI 插件不仅为 Pod 分配 IP 地址,它还会将每个 Pod 所在的节点信息下发给 SDN 交换机。这样当 SDN 交换机接收到 ARP 请求时,将会答复 Pod2 所在节点 Node2 的 MAC 地址,数据包也就顺利地送到了 Node2 上。
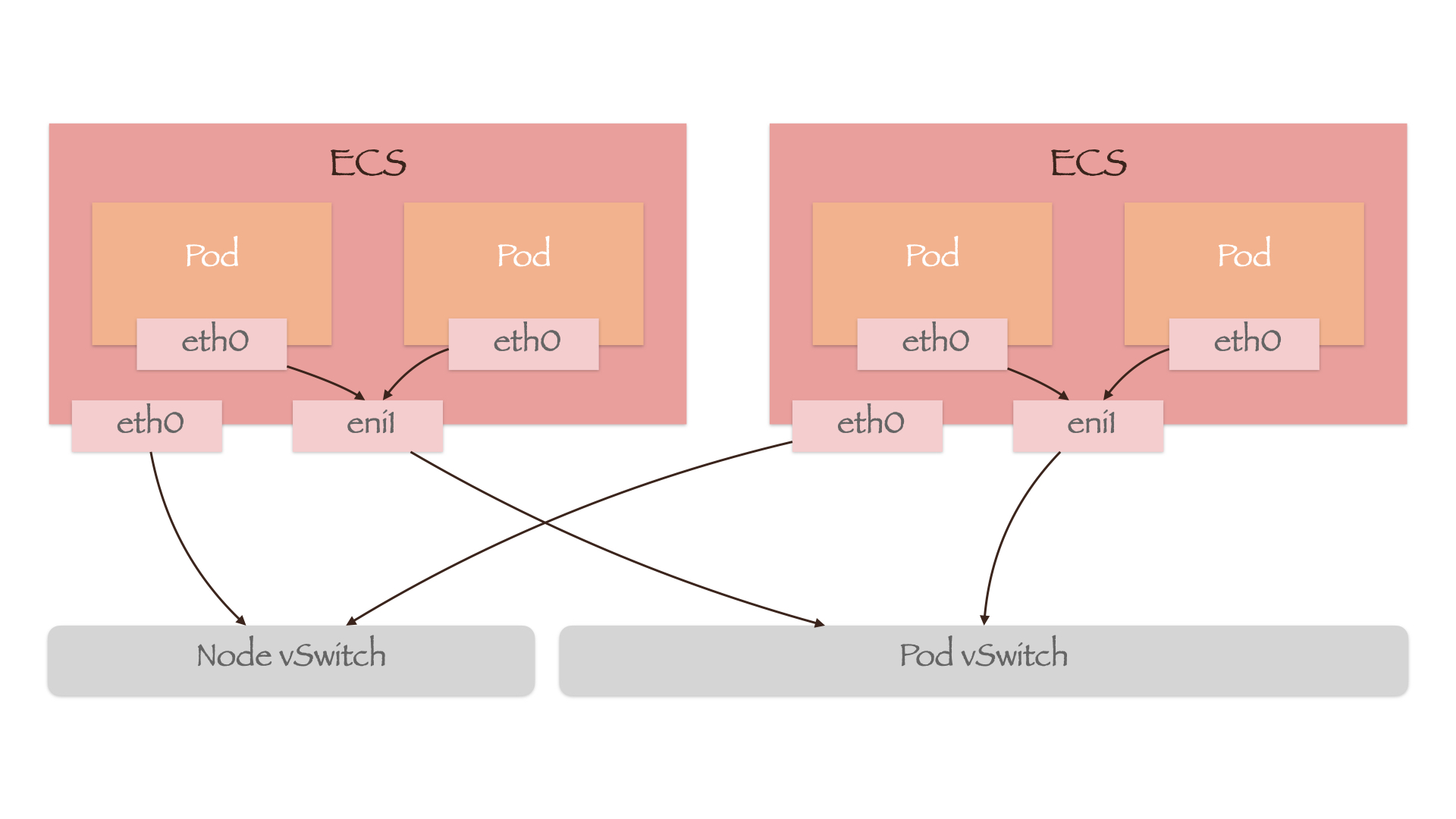
阿里云 Terway 模式的 ACK 服务使用的便是这种网络模型,只不过 Pod 间通信使用的 SDN 交换机不再是节点的交换机(下图中的“Node vSwitch”),而是单独创建的“Pod vSwitch”:
三层
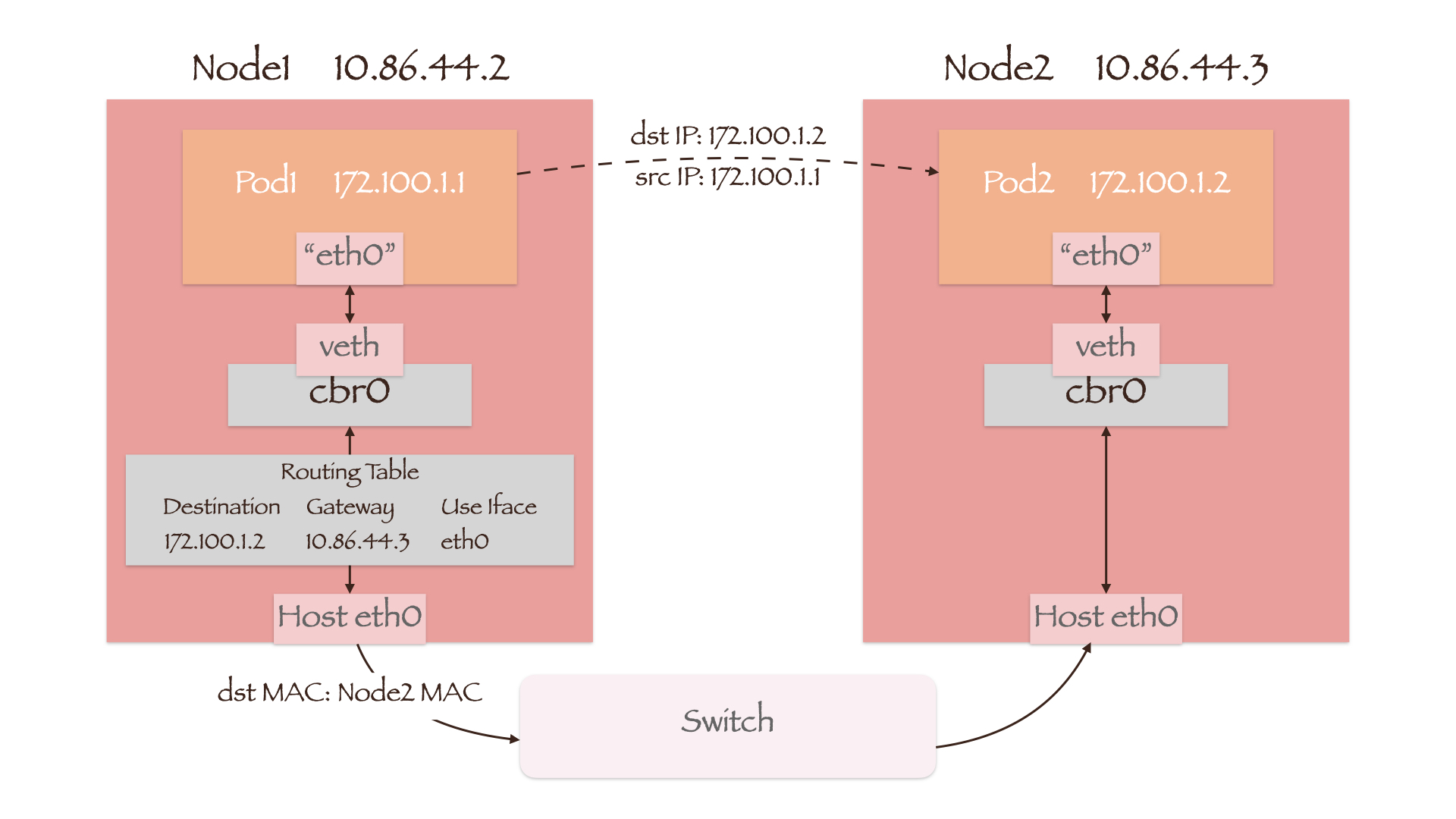
如图所示,Pod 与节点的 IP 地址不再处于同一网段。当 Pod1 向另一节点上的 Pod2 发起通信时,数据包首先通过veth-pair和cbr0进入宿主机内核的路由表(Routing Table)。CNI 插件在该表中添加了若干条路由规则,如目的地址为 Pod2 IP 的网关为 Node2 的 IP。这样数据包的目的 MAC 地址就变为了 Node2 的 MAC 地址,它将会通过交换机发送到 Node2 上。
由于这种实现方式基于三层协议,因此不要求两节点处于同一网段。不过需要将目的地址为 Pod2 IP 的网关设置为 SDN 路由器的 IP,且该路由器能够知晓目的 Pod 所在的节点。这样数据包的目的 MAC 地址就会首先变为 SDN 路由器的 MAC 地址,经过路由器后再变为 Node2 的 MAC 地址:
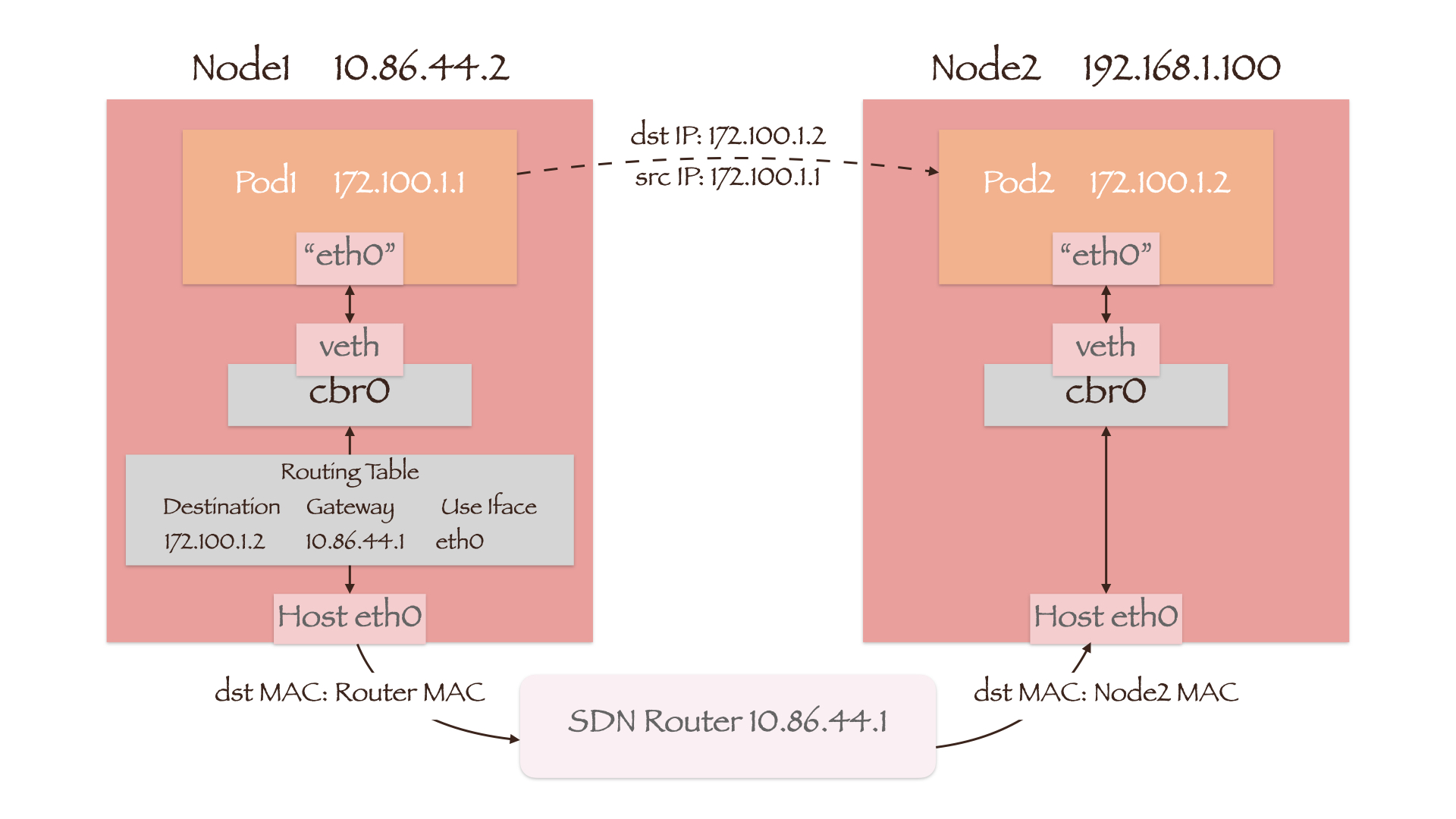
通过上面的讨论我们发现,想要实现三层的 Underlay 网络,需要在多个节点间下发和同步路由表。于是很容易想到用于交换路由信息的 BGP(Border Gateway Protocol)协议:
边界网关协议(英语:Border Gateway Protocol,缩写:BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护 IP 路由表或“前缀”表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP 不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议。
对于 Calico 的 BGP 模式来说,我们可以把集群网络模型视为在每个节点上都部署了一台虚拟路由器。路由器可以与其他节点上的路由器通过 BGP 协议互通,它们被称为一对 BGP Peers。Calico 的默认部署方式为 Full-mesh,即创建一个完整的内部 BGP 连接网,每个节点上的路由器均互为 BGP Peers。这种方式仅适用于 100 个节点以内的中小型集群,在大型集群中使用的效率低下。而 Route Reflectors 模式则将部分节点作为路由反射器,其他节点上的路由器只需与路由反射器互为 BGP Peers。这样便可以大大减少集群中 BGP Peers 的数量,从而提升效率。
Overlay Network
Overlay 网络可以通过多种协议实现,但通常是对 IP 数据包进行一层外部封装(Encapsulation)。这样底层的 Underlay 网络便只会看到外部封装的数据,而无需处理内部的原有数据。Overlay 网络发送数据包的方式取决于其类型和使用的协议,如基于 VxLAN 实现 Overlay 网络,数据包将被外部封装后以 UDP 协议进行发送:
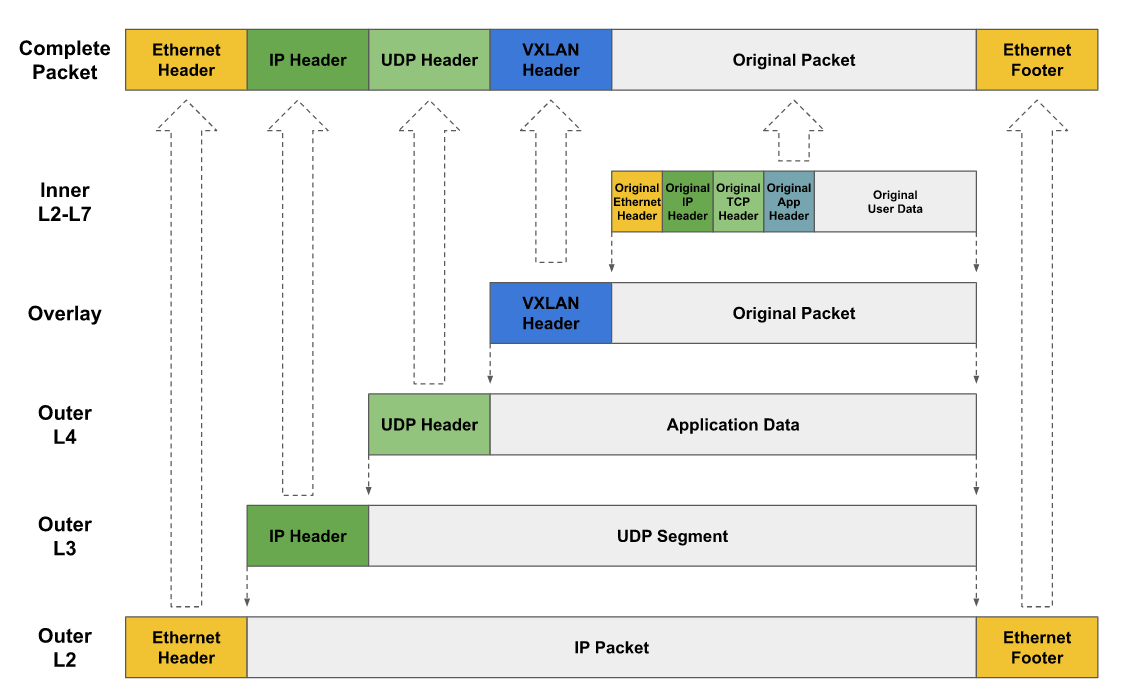
Overlay 网络的实现并不依赖于底层物理网络设备,因此我们就以一个两节点不处于同一网段且 Pod 与节点亦处于不同网段的例子来说明 Overlay 网络中的数据包传递过程。集群网络使用 VxLAN 技术组建,虚拟网络设备 VTEP(Virtual Tunnel End Point)将会完成数据包的封装和解封操作。
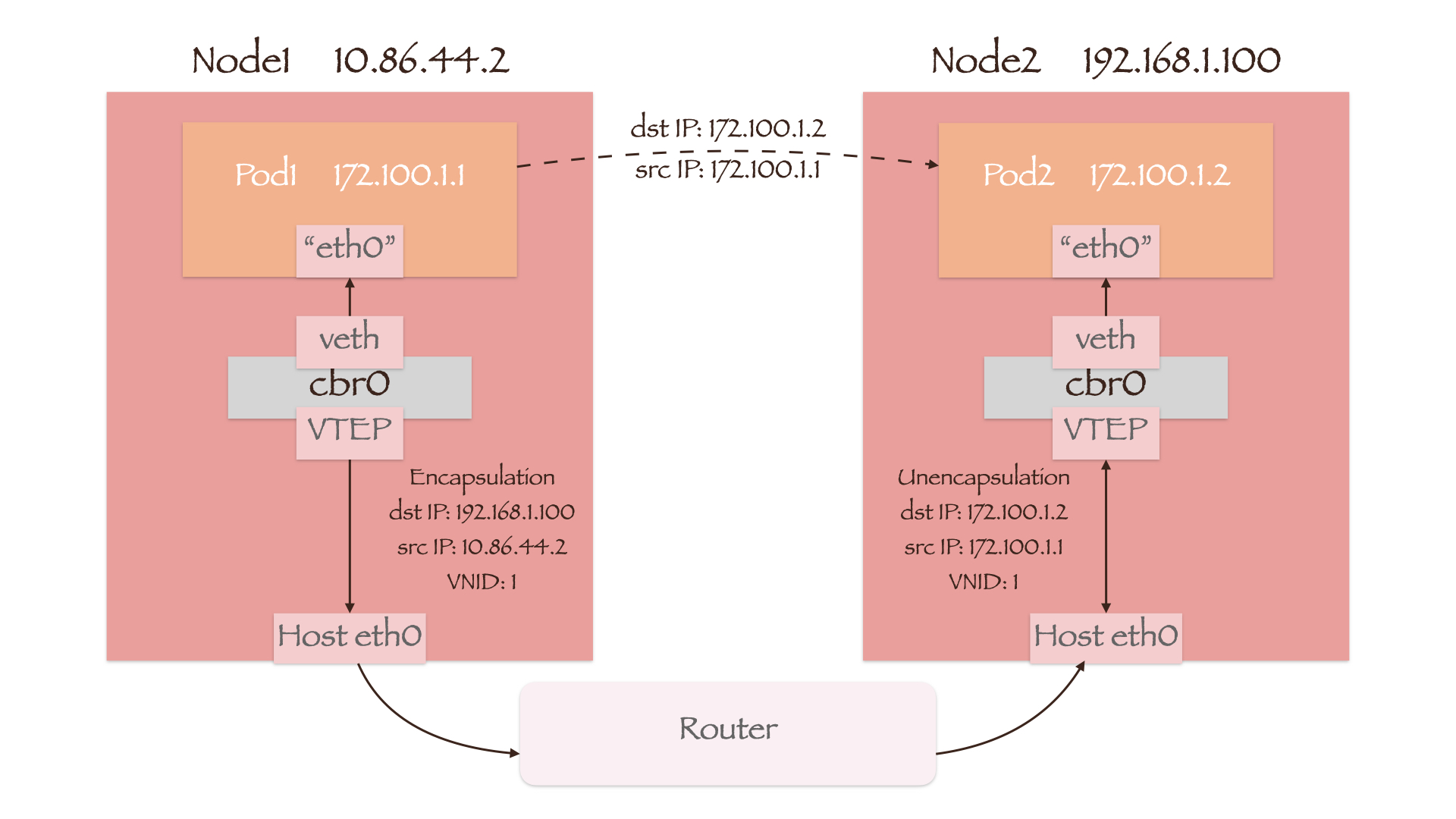
Node1 上的 VTEP 收到 Pod1 发来的数据包后,首先会在本地的转发表中查找目的 Pod 所在节点的 IP,即 192.168.1.100。随后它将本机 IP 地址 10.86.44.2、Node2 的 IP 地址 192.168.1.100 和 Pod1 的 VNID(VxLAN Network Identifier)封装在原始数据包外,从 Node1 的网络接口 eth0 送出。由于新构建的数据包源/目的地址均为节点的 IP,因此外部的路由器可以将其转发到 Node2 上。Node2 中的 VTEP 在接收到数据包后会首先进行解封,若源 VNID(Pod1 的 VNID)与目的 VNID(Pod2 的 VNID)一致,便会根据原始数据包中的目的地址 172.100.1.2 将其发送到 Pod2 上。此处的 VNID 检查,主要是为了实现集群的网络策略管理和多租户隔离。
通过对上述几种 SDN 网络模型的讨论,我们发现只有 Overlay 网络需要对数据包进行封装和解封,因此它的性能相比于 Underlay 网络较差。但 Overlay 网络也有以下优点:
- 对底层网络设备的依赖性最小。即使 Pod 所在的节点发生迁移,依然可以通过 Overlay 网络与原集群实现二层网络的互通;
- VNID 共有 24 位,因此可以构造出约 1600 万个互相隔离的虚拟网络。
Future Work
- 除了 VxLAN 以外,还有哪些技术可以实现 Overlay 网络?它们是怎样传输数据的呢?
本文在讨论 Underlay 网络时提到了 Terway 和 Calico,那么有哪些使用 Overlay 网络的 CNI 插件呢?更新:我在 对 Openshift SDN 网络模型的一些探索 中介绍了基于 Overlay 网络的 Open vSwitch;- 近年来发展迅速的 Cilium 是怎样实现 SDN 网络的?它所依赖的 eBPF 技术又是什么?
参考文献
Software-defined networking - Wikipedia