前言
通常,Kafka 中的每个 Partiotion 中有多个副本 (Replica) 以实现高可用。想象一个场景,Consumer 正在消费 Leader 中 Offset = 10 的数据,而此时 Follower 中只同步到 Offset = 8。那么当 Leader 所在的 Broker 宕机后,当前 Follower 经选举成为新的 Leader,Consumer 再次消费时便会报错。因此,Kafka 引入了 HW(High Watermark,高水位)机制来保证副本数据的可靠性和一致性。
HW 是什么?
HW 定义了消息的可见性,即标识 Partition 中的哪些消息是可以被 Consumer 消费的,只有小于 HW 值的消息才被认为是已备份或已提交的(Committed)。而 LEO(Log End Offset)则表示副本写入下一条消息的 Offset,因此同一副本的 HW 值永远不会大于其 LEO 值。
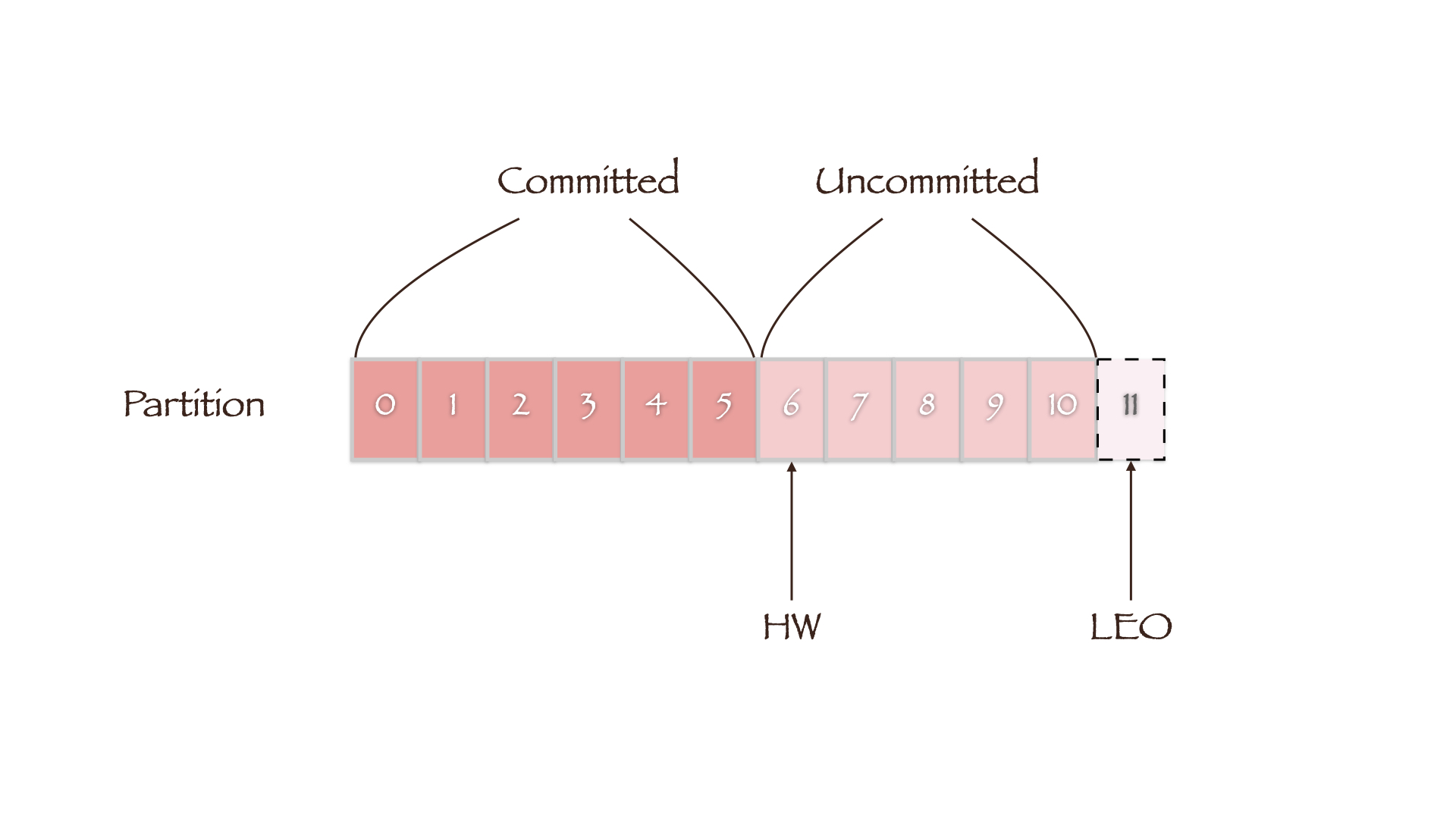
当集群中副本所在的 Broker 发生故障而后恢复时,副本先将数据截断(Truncation)到其 HW 处(LEO 等于 HW),然后再开始向 Leader 同步数据。
HW 的更新机制
每一个副本都保存了其 HW 值和 LEO 值,即 Leader HW(实际上也是 Partition HW)、Leader LEO 和 Follower HW、Follower LEO。而 Leader 所在的 Broker 上还保存了其他 Follower 的 LEO 值,即 Remote LEO。上述几个值的更新流程如下:
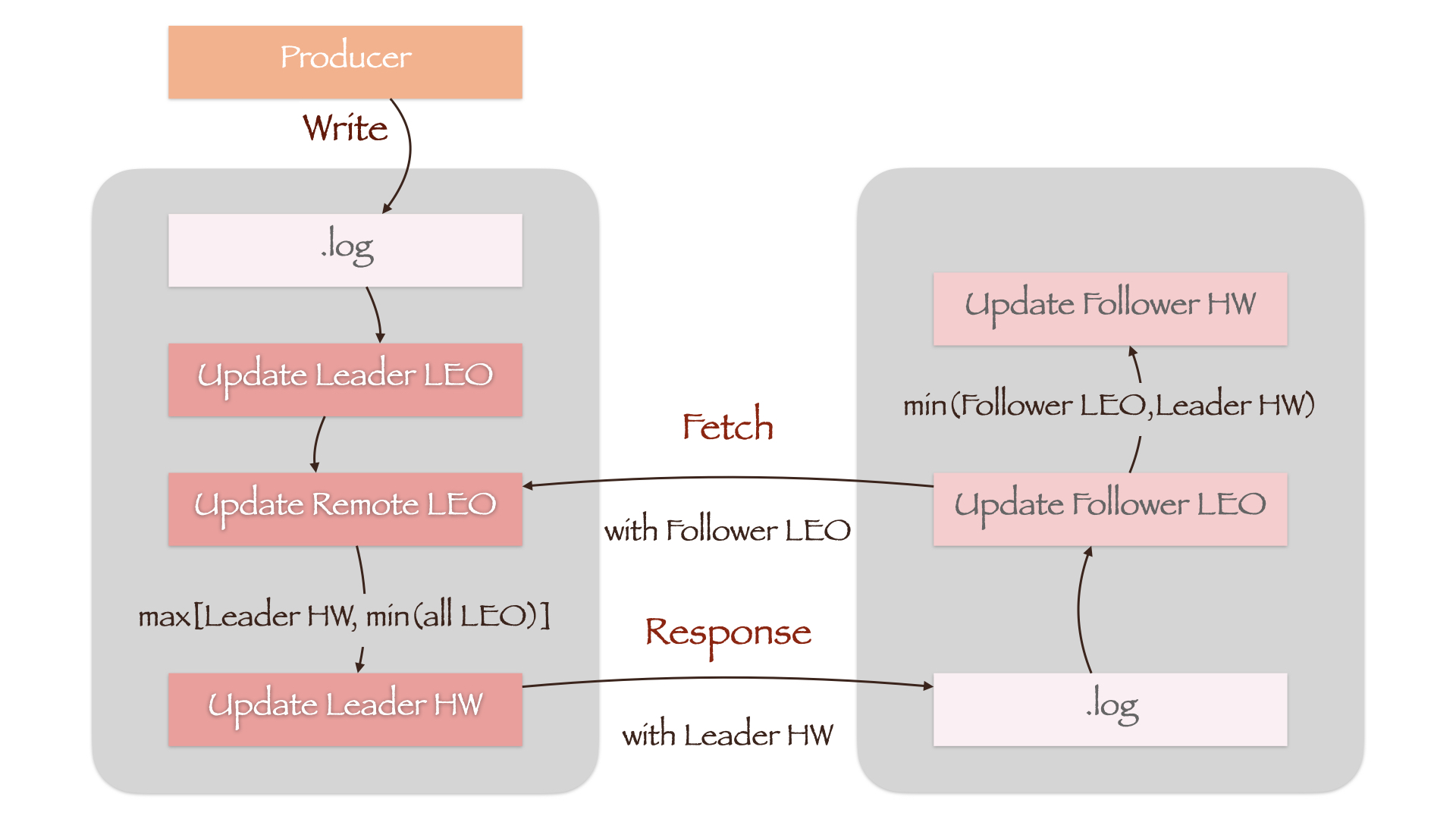
如图所示,当 Producer 向 log 文件写入数据时,Leader LEO 首先被更新。而 Remote LEO 要等到 Follower 向 Leader 发送同步请求(Fetch)时,才会根据请求携带的当前 Follower LEO 值更新。随后,Leader 计算所有副本 LEO 的最小值,将其作为新的 Leader HW。考虑到 Leader HW 只能单调递增,因此还增加了一个 LEO 最小值与当前 Leader HW 的比较,防止 Leader HW 值降低(max[Leader HW, min(All LEO)])。
Follower 在接收到 Leader 的响应(Response)后,首先将消息写入 log 文件中,随后更新 Follower LEO。由于 Response 中携带了新的 Leader HW,Follower 将其与刚刚更新过的 Follower LEO 相比较,取最小值作为 Follower HW(min(Follower LEO, Leader HW))。
举例来说,如果一开始 Leader 和 Follower 中没有任何数据,即所有值均为 0。那么当 Prouder 向 Leader 写入第一条消息,上述几个值的变化顺序如下:
| Leader LEO | Remote LEO | Leader HW | Follower LEO | Follower HW | |
|---|---|---|---|---|---|
| Producer Write | 1 | 0 | 0 | 0 | 0 |
| Follower Fetch | 1 | 0 | 0 | 0 | 0 |
| Leader Update HW | 1 | 0 | 0 | 0 | 0 |
| Leader Response | 1 | 0 | 0 | 1 | 0 |
| Follower Update HW | 1 | 0 | 0 | 1 | 0 |
| Follower Fetch | 1 | 1 | 0 | 1 | 0 |
| Leader Update HW | 1 | 1 | 1 | 1 | 0 |
| Leader Response | 1 | 1 | 1 | 1 | 0 |
| Follower Update HW | 1 | 1 | 1 | 1 | 1 |
HW 的隐患
通过上面的表格我们发现,Follower 往往需要进行两次 Fetch 请求才能成功更新 HW。Follower HW 在某一阶段内总是落后于 Leader HW,因此副本在根据 HW 值截取数据时将有可能发生数据的丢失或不一致。
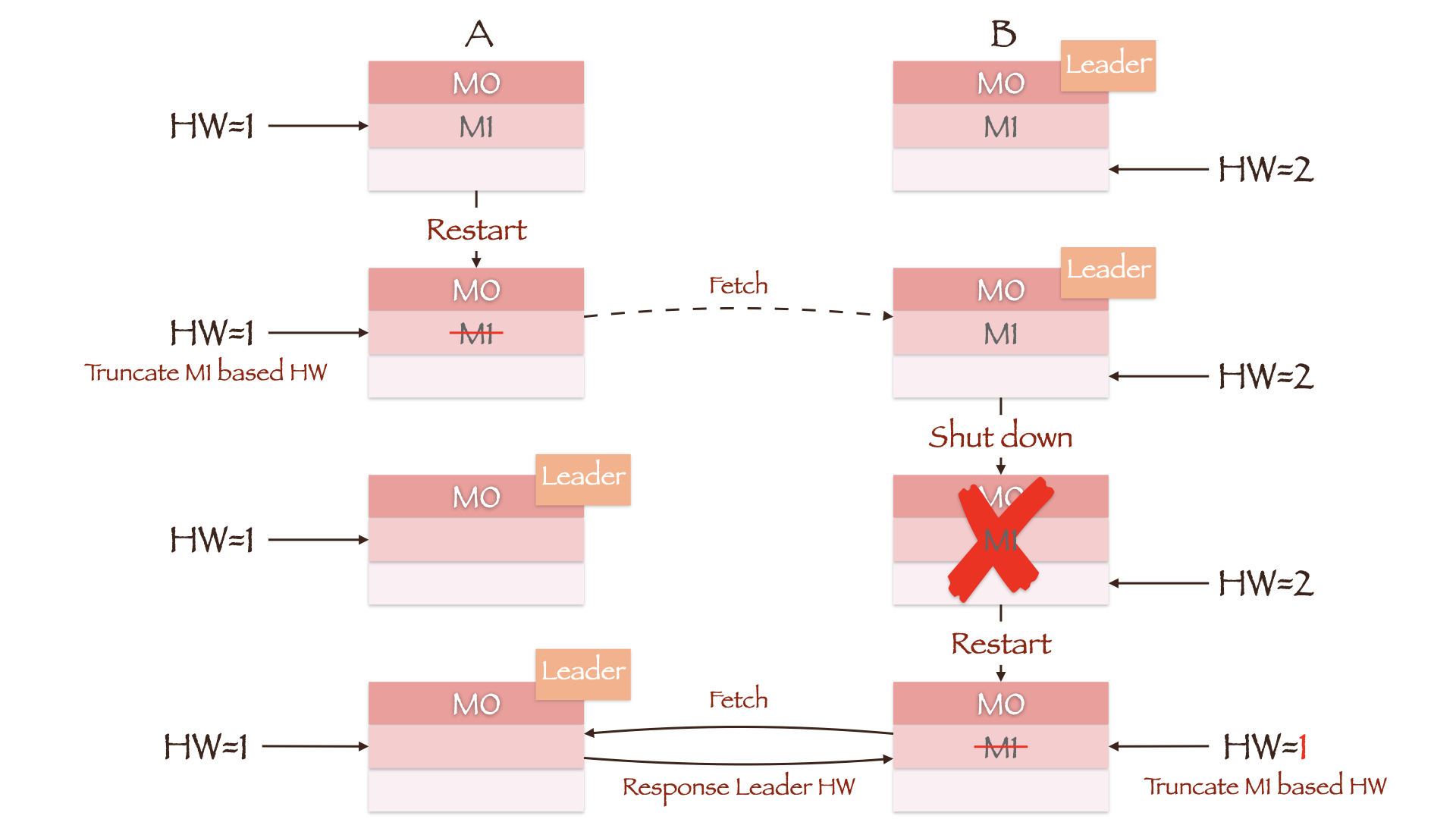
图中两副本的 LEO 均为 2,但 Leader 副本 B 上的 HW 为 2,Follower 副本 A 上的 HW 为 1。正常情况下,副本 A 将在接收 Leader Response 后根据 Leader HW 更新其 Follower HW 为 2。但假如此时副本 A 所在的 Broker 重启,它会把 Follower LEO 修改为重启前自身的 HW 值 1,因此数据 M1(Offset = 1)被截断。当副本 A 重新向副本 B 发送同步请求时,如果副本 B 所在的 Broker 发生宕机,副本 A 将被选举成为新的 Leader。即使副本 B 所在的 Broker 能够成功重启且其 LEO 值依然为 2,但只要它向当前 Leader(副本 A)发起同步请求后就会更新其 HW 为 1(计算min(Follower LEO, Leader HW)),数据 M1(Offset = 1)随即被截断。如果min.insync.replicas参数为 1,那么 Producer 不会因副本 A 没有同步成功而重新发送消息,M1 也就永远丢失了。
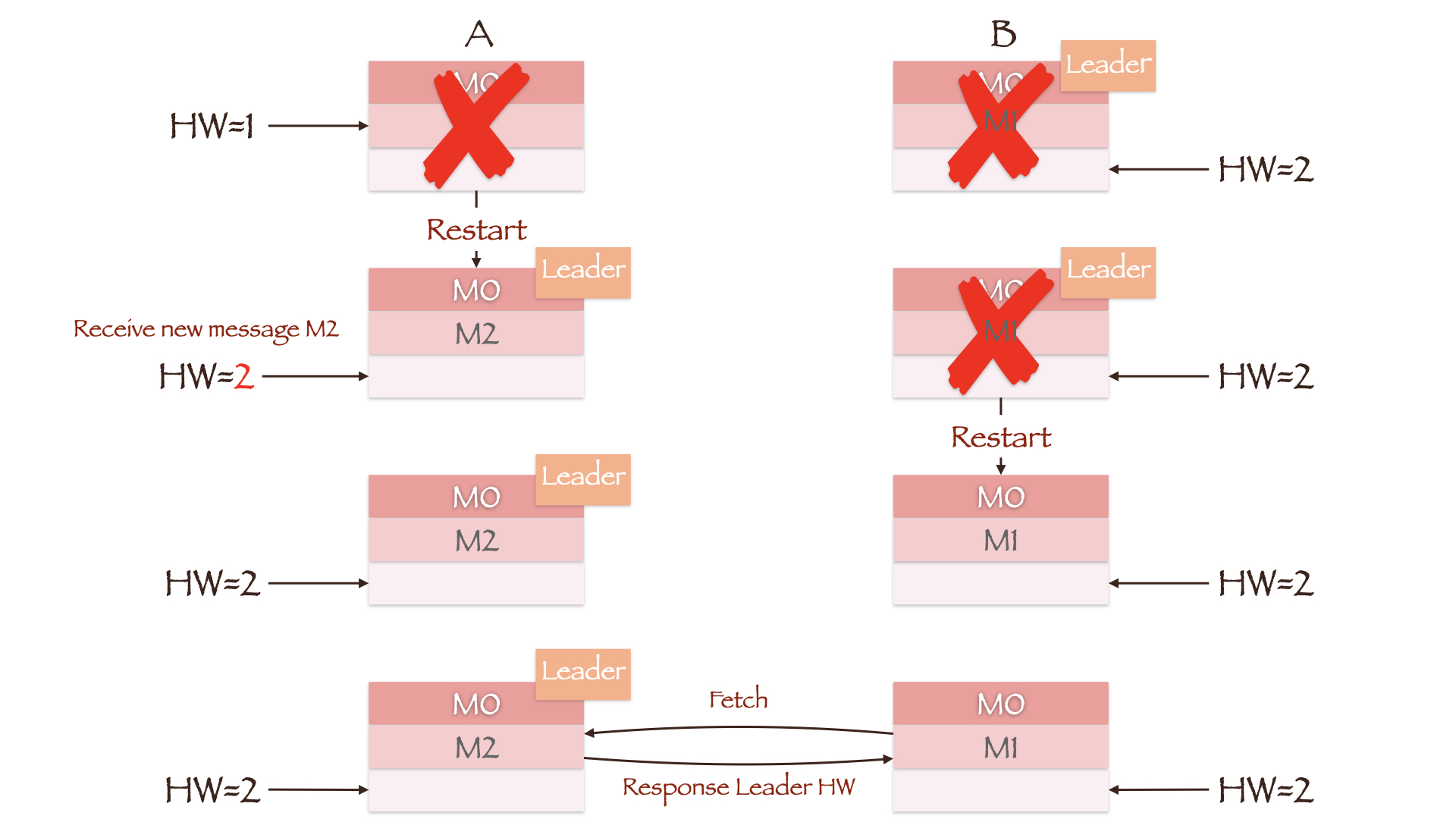
图中 Leader 副本 B 写入了两条数据 M0 和 M1,Follower 副本 A 只写入了一条数据 M0。此时 Leader HW 为 2,Follower HW 为 1。如果在 Follower 同步第二条数据前,两副本所在的 Broker 均发生重启且副本 B 所在的 Broker 先重启成功,那么副本 A 将成为新的 Leader。这时 Producer 向其写入数据 M2,副本 A 作为集群中的唯一副本,更新其 HW 为 2。当副本 B 所在的 Broker 重启后,它将向当前的 Leader 副本 A 同步数据。由于两者的 HW 均为 2,因此副本 B 不需要进行任何截断操作。在这种情况下,副本 B 中的数据为重启前的 M0 和 M1,副本 A 中的数据却是 M0 和 M2,副本间的数据出现了不一致。
Leader Epoch
Kakfa 引入 Leader Epoch 后,Follower 就不再参考 HW,而是根据 Leader Epoch 信息来截断 Leader 中不存在的消息。这种机制可以弥补基于 HW 的副本同步机制的不足,Leader Epoch 由两部分组成:
- Epoch:一个单调增加的版本号。每当 Leader 副本发生变更时,都会增加该版本号。Epoch 值较小的 Leader 被认为是过期 Leader,不能再行使 Leader 的权力;
- 起始位移(Start Offset):Leader 副本在该 Epoch 值上写入首条消息的 Offset。
举例来说,某个 Partition 有两个 Leader Epoch,分别为 (0, 0) 和 (1, 100)。这意味该 Partion 历经一次 Leader 副本变更,版本号为 0 的 Leader 从 Offset = 0 处开始写入消息,共写入了 100 条。而版本号为 1 的 Leader 则从 Offset = 100 处开始写入消息。
每个副本的 Leader Epoch 信息既缓存在内存中,也会定期写入消息目录下的 leaderer-epoch-checkpoint 文件中。当一个 Follower 副本从故障中恢复重新加入 ISR 中,它将:
- 向 Leader 发送 LeaderEpochRequest,请求中包含了 Follower 的 Epoch 信息;
- Leader 将返回其 Follower 所在 Epoch 的 Last Offset;
- 如果 Leader 与 Follower 处于同一 Epoch,那么 Last Offset 显然等于 Leader LEO;
- 如果 Follower 的 Epoch 落后于 Leader,则 Last Offset 等于 Follower Epoch + 1 所对应的 Start Offset。这可能有点难以理解,我们还是以 (0, 0) 和 (1, 100) 为例进行说明:Offset = 100 的消息既是 Epoch = 1 的 Start Offset,也是 Epoch = 0 的 Last Offset;
- Follower 接收响应后根据返回的 Last Offset 截断数据;
- 在数据同步期间,只要 Follower 发现 Leader 返回的 Epoch 信息与自身不一致,便会随之更新 Leader Epoch 并写入磁盘。
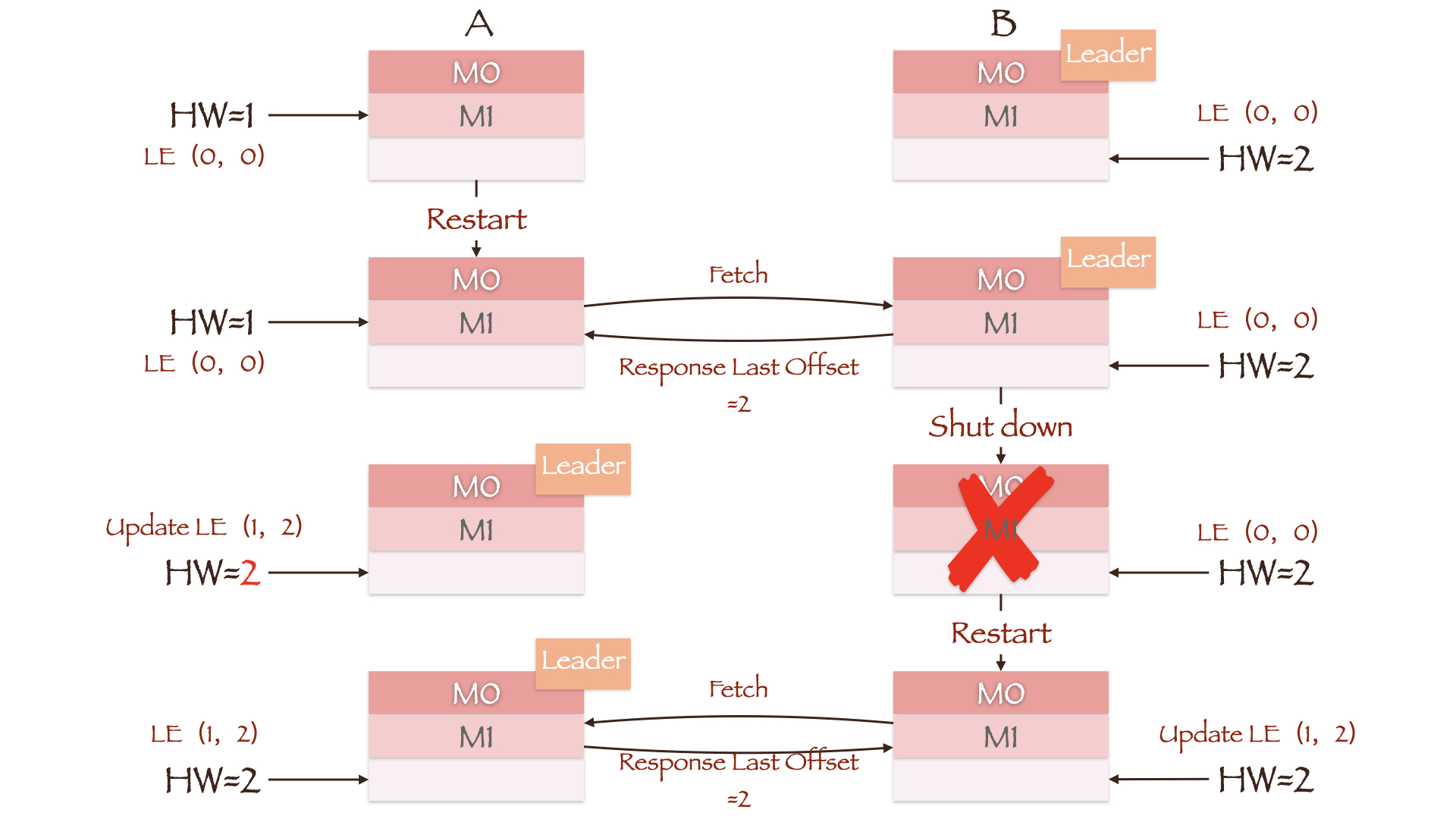
在刚刚介绍的数据丢失场景中,副本 A 所在的 Broker 重启后根据自身的 HW 将数据 M1 截断。而现在,副本 A 重启后会先向副本 B 发送一个请求(LeaderEpochRequest)。由于两副本的 Epoch 均为 0,副本 B 返回的 Last Offset 为 Leader LEO 值 2。而副本 A 上并没有 Offset 大于等 2 的消息,因此无需进行数据截断,同时其 HW 也会更新为 2。之后副本 B 所在的 Broker 宕机,副本 A 成为新的 Leader,Leader Epoch 随即更新为 (1, 2)。当副本 B 重启回来并向当前 Leader 副本 A 发送 LeaderEpochRequest,得到的 Last Offset 为 Epoch = 1 对应的 Start Offset 值 2。同样,副本 B 中消息的最大 Offset 值只有 1,因此也无需进行数据截断,消息 M1 成功保留了下来。
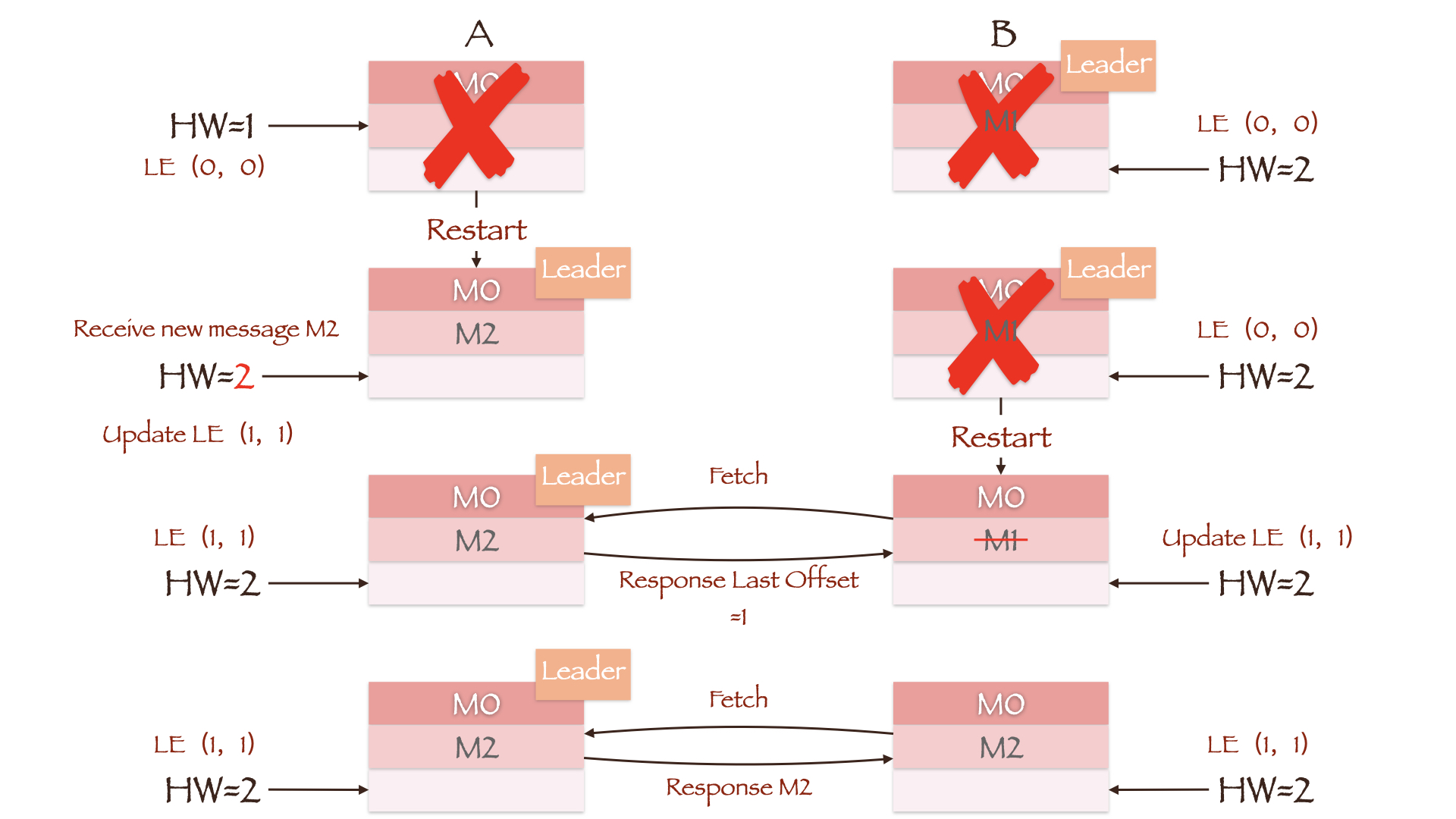
在刚刚介绍的数据不一致场景中,由于最后两副本 HW 值相等,因此没有将不一致的数据截断。而现在,副本 A 重启后并便会更新 Leader Epoch 为 (1, 1),同时也会更新其 HW 值为 2。副本 B 重启后向当前 Leader 副本 A 发送 LeaderEpochRequest,得到的 Last Offset 为 Epoch = 1 对应的 Start Offset 值 1,因此截断 Offset = 1 的消息 M1。这样只要副本 B 再次发起请求同步消息 M2,两副本的数据便可以保持一致。
值得一提的是,Leader Epoch 机制在min.insync.replicas参数为 1 且unclean.leader.election.enabled参数为true时依然无法保证数据的可靠性。感兴趣的读者可以阅读 KIP-101 - Alter Replication Protocol to use Leader Epoch rather than High Watermark for Truncation 文中的附录部分。
参考文献
KIP-101 - Alter Replication Protocol to use Leader Epoch rather than High Watermark for Truncation