原书中的代码片段基于 Go 1.15,笔记则根据 Go 1.22 版本的更新进行了相应替换。
我们通常会从两个维度描述数组:数组中存储的元素类型(Type)和数组最大能存储的元素个数(Bound)。
1
2
3
4
| type Array struct {
Elem *Type // element type
Bound int64 // number of elements; <0 if unknown yet
}
|
Go 语言数组在初始化之后大小就无法改变。存储元素类型相同、但大小不同的数组类型在 Go 语言看来也是完全不同的,只有两个条件都相同才是同一类型。
编译期间的数组类型是由 cmd/compile/internal/types.NewArray 函数生成的:
1
2
3
4
5
6
7
8
9
10
11
| func NewArray(elem *Type, bound int64) *Type {
if bound < 0 {
base.Fatalf("NewArray: invalid bound %v", bound)
}
t := newType(TARRAY)
t.extra = &Array{Elem: elem, Bound: bound}
if elem.HasShape() {
t.SetHasShape(true)
}
return t
}
|
Go 语言的数组有两种不同的创建方式,一种是显式的指定数组大小,另一种是使用[...]T声明数组。如下两种声明方式在运行期间得到的结果是完全相同的:
1
2
| arr1 := [3]int{1, 2, 3}
arr2 := [...]int{1, 2, 3}
|
不过第一种方式声明的数组的大小在 类型检查 阶段就会被提取出来,而第二种方式则需要编译器通过遍历元素来计算。因此,[...]T 这种初始化方式其实是 Go 语言为我们提供的一种语法糖。
对于一个由字面量(Literal)组成的数组,根据数组元素数量的不同,编译器会在负责初始化字面量的 cmd/compile/internal/walk.anylit 函数中做出两种不同的优化:
- 当元素数量小于或者等于 4 个时,会直接将数组中的元素放置在栈上;
- 当元素数量大于 4 个时,会将数组中的元素放置到静态区并在运行时复制到栈中。
举例来说,[3]int{1, 2, 3}会被拆分成一个声明变量的表达式和几个赋值表达式:
1
2
3
4
| var arr [3]int
arr[0] = 1
arr[1] = 2
arr[2] = 3
|
而[5]int{1, 2, 3, 4, 5}的初始化过程则等效于如下伪码:
1
2
3
4
5
6
7
8
| var arr [5]int
// 元素存储于静态区
statictmp_0[0] = 1
statictmp_0[1] = 2
statictmp_0[2] = 3
statictmp_0[3] = 4
statictmp_0[4] = 5
arr = statictmp_0
|
无论是在栈上还是静态存储区,数组在内存中都是一连串的内存空间,我们通过指向数组开头的指针、元素的数量以及元素类型占的空间大小表示数组。
Go 语言中可以在编译期间的静态类型检查判断数组越界,但是如果使用变量去访问数组或者字符串时,我们就需要 Go 语言运行时阻止不合法的访问:
1
2
3
4
| // 静态类型检查
arr[4]: invalid argument: index 4 out of bounds [0:3]
// 运行时 runtime.panicIndex
arr[i]: panic: runtime error: index out of range [4] with length 3
|
切片,即动态数组,其长度并不固定,所以声明时只需要指定切片中的元素类型:
编译期间的切片是 cmd/compile/internal/types.Slice 类型的,只确定了元素的类型:
1
2
3
| type Slice struct {
Elem *Type // element type
}
|
在运行时则由 internal/unsafeheader.Slice 结构体表示:
1
2
3
4
5
| type SliceHeader struct {
Data unsafe.Pointer // 指向底层数组的指针
Len int // 当前切片的长度
Cap int // 当前切片的容量,即底层数组的大小
}
|
由于大量开发者使用 reflect.StringHeader 和 reflect.SliceHeader 实现零复制的字符串/字节数组转换而产生诸多内存泄露问题,两者在 Go 1.20 版本中被弃用,详见:unsafe: add StringData, String, SliceData。切片和字符串的运行时表示目前为:unsafeheader.Slice 和 unsafeheader.String,区别在于Data字段的类型由uintptr改为unsafe.Pointer。
因此我们可以将切片理解成一片连续的内存空间(底层数组)以及长度与容量的标识:
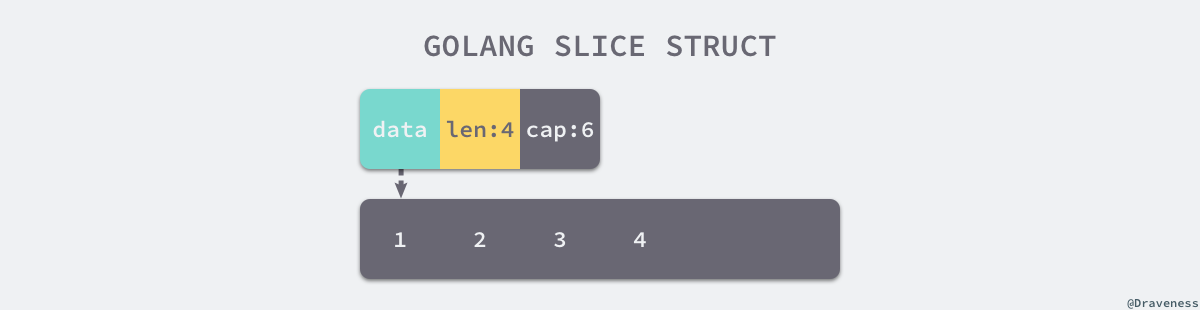
Go 语言中支持三种初始化切片的方式:
1
2
3
| arr[0:3] or slice[0:3] // 通过下标获取数组或切片的一部分
slice := []int{1, 2, 3} // 使用字面量初始化新切片
slice := make([]int, 10) // 使用关键字 make 创建切片
|
使用下标初始化切片不会复制原数组或者原切片中的数据,它只会创建一个指向原数组的切片结构体,所以修改新切片的数据也会修改原切片。这种操作是所有创建切片的方法中最为底层的。
当我们使用字面量[]int{1, 2, 3}创建新的切片时,cmd/compile/internal/walk.slicelit 函数会在编译期间将它展开成如下所示的代码片段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 根据切片元素数量创建底层数组 vstat,位于栈上
var vstat [3]int
// 将字面量元素存储到初始化的数组中
// 如 vstat[0] = 1
vstat = constpart{}
// 在堆上分配一块存储 [3]int 数组的内存
// 并返回指向该内存的指针 vauto
var vauto *[3]int = new([3]int)
// 将数组 vstat 复制到 vauto 指向的数组
// 注意,Go 语言的数组名是值而非 C 中的隐式指针
*vauto = vstat
vauto[i] = dynamic part
// 通过 [:] 操作获取一个底层使用 vauto 的切片
slice := vauto[:]
|
最后一步实际上就是使用下标创建切片。
与其他两种方法相比,使用make关键字创建切片时,很多工作需要运行时的参与。类型检查期间的 cmd/compile/internal/typecheck.typecheck1 函数会校验len是否传入,以及cap是否大于或等于len。
随后 cmd/compile/internal/walk.walkMakeSlice 会根据切片的大小以及是否发生内存逃逸进行不同的处理:如果当前的切片不会发生逃逸并且切片非常小的时候,make([]int, 3, 4) 会在编译阶段被直接转换成如下所示的代码:
1
2
| var arr [4]int
n := arr[:3]
|
而当切片发生逃逸或者非常大时,运行时需要 runtime.makeslice 在堆上初始化切片:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| func makeslice(et *_type, len, cap int) unsafe.Pointer {
// 计算切片占用的内存空间
// 内存空间 = 元素大小 * 切片容量
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
// 检查内存是否发生溢出或超出最大可分配内存
// 长度是否小于 0 或长度是否大于容量
if overflow || mem > maxAlloc || len < 0 || len > cap {
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// 申请一块连续的内存空间
return mallocgc(mem, et, true)
}
|
在之前版本的 Go 语言中,该函数最后会将数组指针、长度和容量合成一个 runtime.slice 结构体。但是从 cmd/compile: move slice construction to callers of makeslice 提交之后,这项工作就交给了函数的调用方。后者会在编译期间构建切片结构体,而 runtime.makeslice 仅返回指向底层数组的指针。
使用len和cap获取长度或者容量是切片最常见的操作,编译器将这它们看成两种特殊操作,即 OLEN 和 OCAP。
在编译期间,对切片中元素的访问操作 OINDEX 会被转换成对地址的直接访问,而包含range关键字的遍历则被转换成形式更简单的循环。
如果 append 返回的新切片不会覆盖原切片:
1
2
3
4
5
6
7
8
9
10
11
12
| // new_slice := append(s, 1, 2, 3)
ptr, len, cap := s
len += 3
if uint(len) > uint(cap) {
ptr, len, cap = growslice(ptr, len, cap, 3, typ)
// Note that len is unmodified by growslice.
}
// with write barriers, if needed:
*(ptr+(len-3)) = e1
*(ptr+(len-2)) = e2
*(ptr+(len-1)) = e3
return makeslice(ptr, len, cap)
|
如果 append 返回的切片会覆盖原切片:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| // s = append(s, 1, 2, 3)
a := &s
ptr, len, cap := s
len += 3
if uint(len) > uint(cap) {
ptr, len, cap = growslice(ptr, len, cap, 3, typ)
vardef(a) // if necessary, advise liveness we are writing a new a
*a.cap = cap // write before ptr to avoid a spill
*a.ptr = ptr // with write barrier
}
*a.len = len
// with write barriers, if needed:
*(ptr+(len-3)) = e1
*(ptr+(len-2)) = e2
*(ptr+(len-1)) = e3
|
两者的逻辑其实差不多,最大的区别在于得到的新切片是否会赋值回原变量。如果我们选择覆盖原有的变量,就不需要担心切片发生拷贝影响性能,因为 Go 语言编译器已经对这种常见的情况做出了优化。
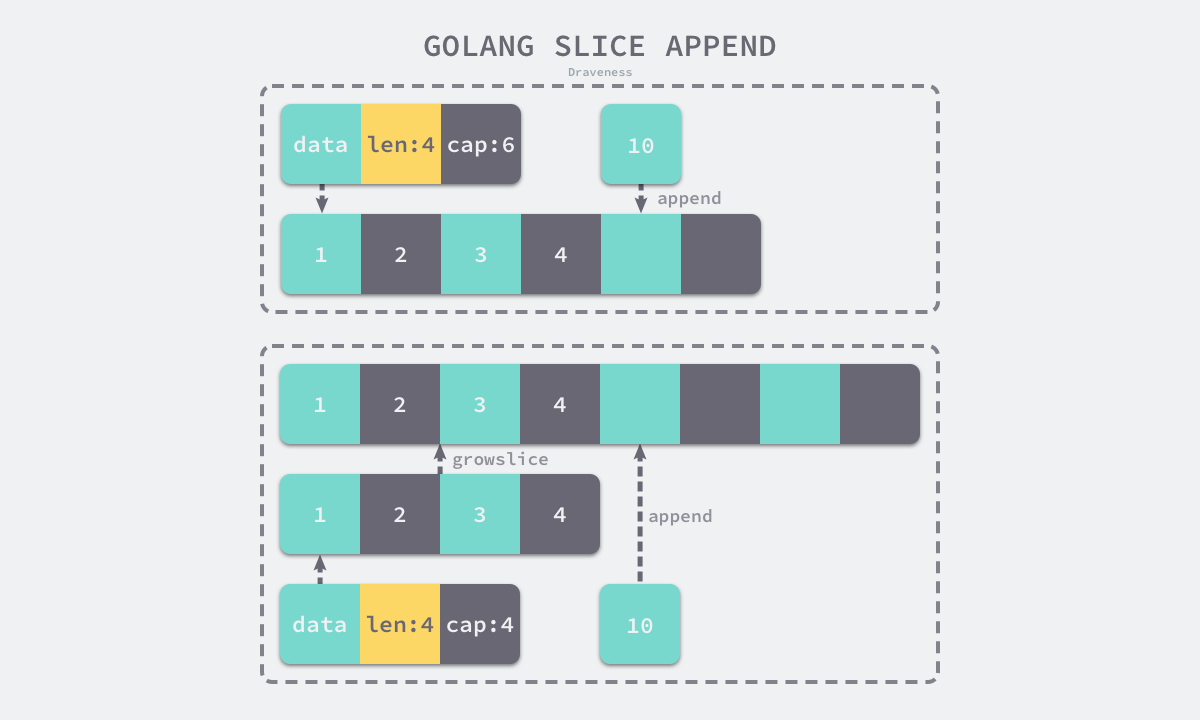
扩容是为切片分配新的内存空间并复制原切片中元素的过程,runtime.growslice 函数最终会返回一个新的切片,其中包含了新的数组指针、大小和容量。runtime.nextslicecap 则根据切片的所需长度和当前容量选择不同的策略进行扩容:
- 当所需长度 newLen 超过原容量 oldCap 的 2 倍时,直接以所需长度作为新容量 newcap;
- 否则:
- 小切片(原容量 < 256):翻倍扩容;
- 大切片(原容量 ≥ 256):
- 渐进扩容(约 1.25 倍增长),直到新容量超过所需长度;
- 若新容量溢出则直接使用所需长度作为新容量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| // nextslicecap computes the next appropriate slice length.
func nextslicecap(newLen, oldCap int) int {
newcap := oldCap
doublecap := newcap + newcap
if newLen > doublecap {
return newLen
}
const threshold = 256
if oldCap < threshold {
return doublecap
}
for {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) >> 2
// We need to check `newcap >= newLen` and whether `newcap` overflowed.
// newLen is guaranteed to be larger than zero, hence
// when newcap overflows then `uint(newcap) > uint(newLen)`.
// This allows to check for both with the same comparison.
if uint(newcap) >= uint(newLen) {
break
}
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
return newLen
}
return newcap
}
|
当我们执行如下代码时,会触发 runtime.growslice 函数扩容arr切片并传入期望的新容量 5,此时期望分配的内存大小为 40 字节。不过运行时会调用 runtime.roundupsize 将切片占用的内存大小对齐到 48 字节,因此新切片的容量为 48 / 8 = 6:
1
2
| var arr []int64
arr = append(arr, 1, 2, 3, 4, 5)
|
无论是编译期间复制还是运行时复制,两种复制方式都会通过 runtime.memmove 将整块内存的内容复制到目标的内存区域中:
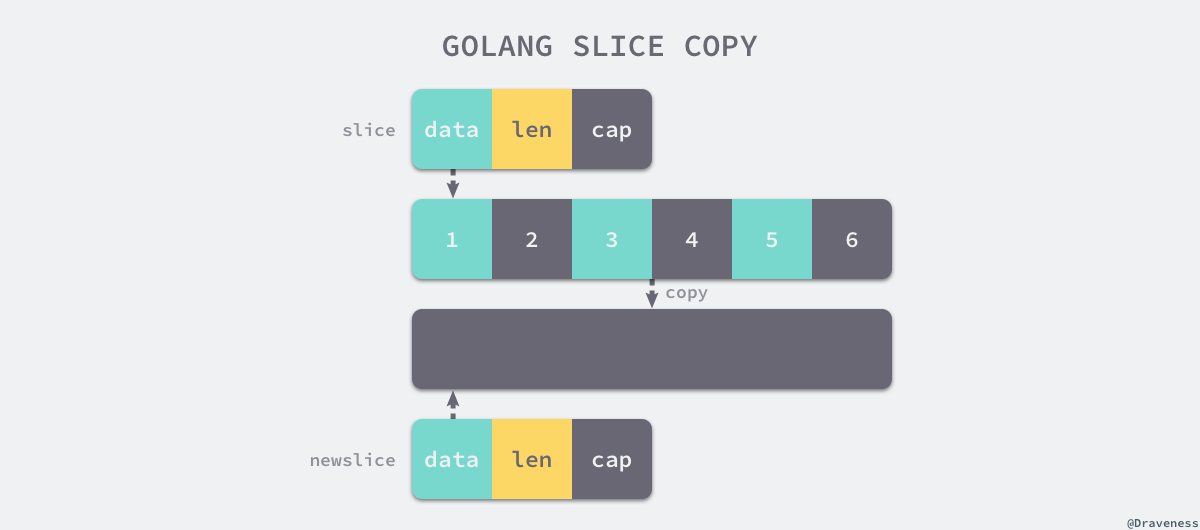
相比于依次复制元素,这种方式能够提供更好的性能。不过,整块复制内存仍然会占用非常多的资源,对大切片执行复制操作时一定要注意对性能的影响。
哈希表是计算机科学中的最重要数据结构之一,这不仅因为它 𝑂(1) 的读写性能非常优秀,还因为它提供了键值之间的映射。想要实现一个性能优异的哈希表,需要注意两个关键点 —— 哈希函数和冲突解决方法。
哈希函数映射的结果一定要尽可能均匀,结果不均匀的哈希函数会带来更多的哈希冲突以及更差的读写性能。
解决哈希冲突的常见方法有开放寻址法和拉链法。
这种方法的核心思想是依次探测和比较数组中的元素以判断目标键值对是否存在于哈希表中,此时实现哈希表底层的数据结构是数组。不过因为数组的长度有限,向哈希表写入键值对时会从如下的索引开始遍历:
1
| index := hash("Key3") % array.len
|
如下图所示,当 Key3 与已经存入哈希表中的两个键值对 Key1 和 Key2 发生冲突时,Key3 会被写入 Key2 后面的空闲位置。当我们再去读取 Key3 对应的值时就会先获取键的哈希并取模,这会先帮助我们找到 Key1,找到 Key1 后发现它与 Key 3 不相等,所以会继续查找后面的元素,直到内存为空或者找到目标元素。
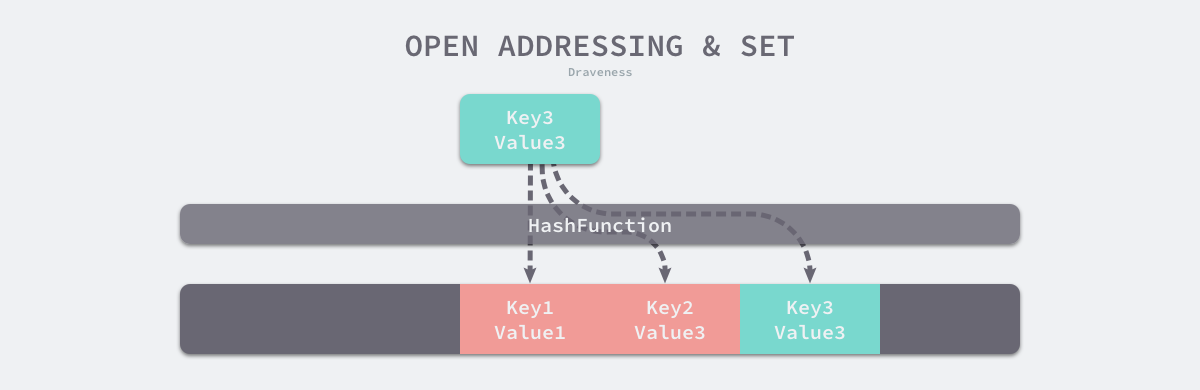
开放寻址法中对性能影响最大的是装载因子,它是数组中元素的数量与数组大小的比值。随着装载因子的增加,线性探测的平均用时就会逐渐增加,这会影响哈希表的读写性能。当装载率超过 70% 之后,哈希表的性能就会急剧下降。而一旦装载率达到 100%,整个哈希表就会完全失效,这时查找和插入元素的时间复杂度都是 𝑂(𝑛),即需要遍历数组中的全部元素。
大多数编程语言都采用拉链法,它的平均查找时间较短且可以动态申请内存以减少内存占用。实现拉链法一般会使用数组加上链表,我们可以将它看成可以扩展的二维数组:
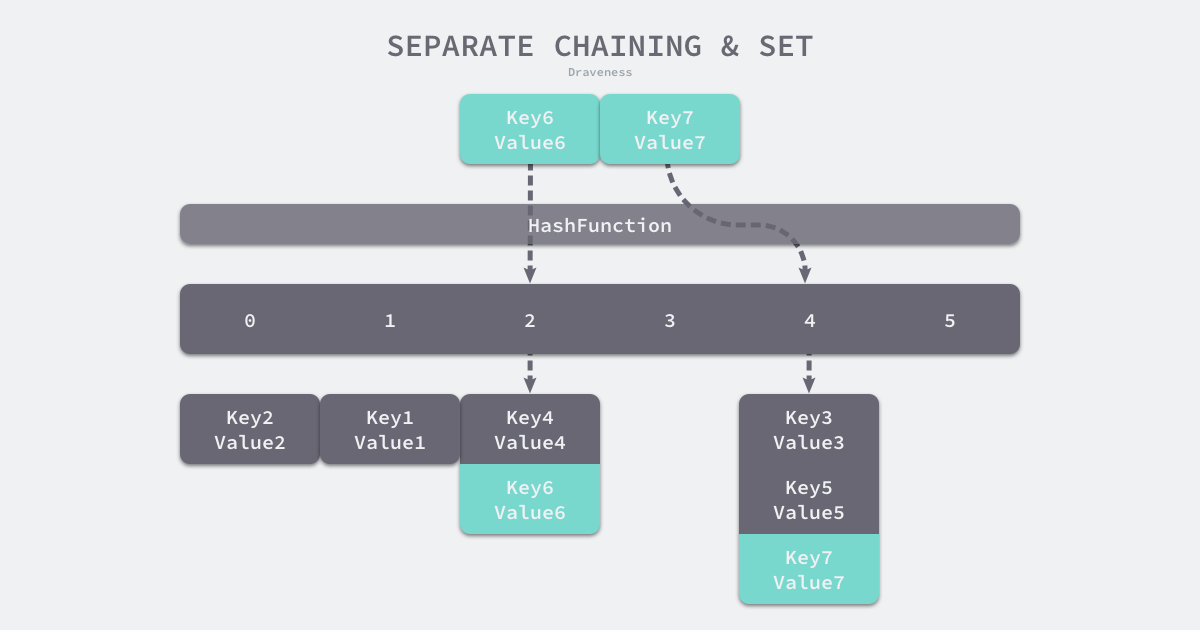
和开放地址法一样,选择桶(链表)的方式是直接对哈希函数返回的结果取模:
1
| index := hash("Key6") % array.len
|
如上图所示,Key 6 的索引为 2,此时遍历 2 号桶中的链表时可能会遇到两种情况:
- 找到键相同的键值对,则读取/写入键对应的值;
- 未找到键相同的键值对,则返回该键不存在(读取)/在链表的末尾追加新的键值对(写入);
拉链法的装载因子等于元素数量除以桶的数量,装载因子越大(一般不会超过 1),读写性能就越差。当装载因子较大时会触发哈希的扩容,即创建更多的桶来存储哈希中的元素,保证性能不会出现严重的下降。
Go 语言运行时同时使用了多个数据结构组合表示哈希表,其中 runtime.hmap 是最核心的结构体:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| type hmap struct {
count int // 当前哈希表中的元素数量
flags uint8
B uint8 // 当前哈希表正常桶的数量为 2 ^ B
noverflow uint16 // 使用的溢出桶数量
hash0 uint32 // 为哈希函数引入随机性种子
buckets unsafe.Pointer // 指向 bmap 数组的指针
oldbuckets unsafe.Pointer // 扩容时保存的旧桶,大小为当前的一半
nevacuate uintptr // 标识扩容进度,小于此地址的桶已迁移完成
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap // 已使用的溢出桶地址
oldoverflow *[]*bmap // 扩容时旧桶使用的溢出桶地址
nextOverflow *bmap // 指向下一个空闲的溢出桶
}
|
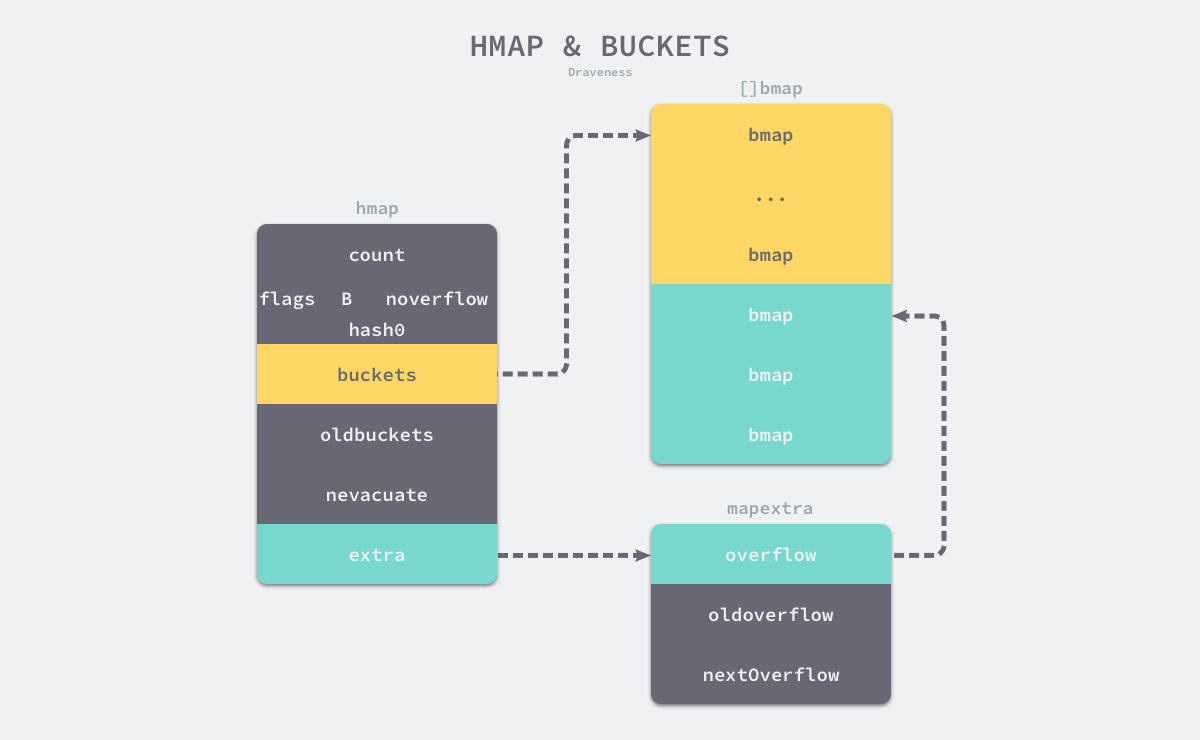
如上图所示哈希表 runtime.hmap 的桶是 runtime.bmap,后者能存储 8 个键值对。当哈希表中存储的数据过多,单个桶已经装满时就会使用extra.nextOverflow中的桶存储溢出的数据。
上述两种不同的桶在内存中是连续存储的,我们在这里将它们分别称为正常桶和溢出桶,上图中黄色的 runtime.bmap 就是正常桶,绿色的 runtime.bmap 是溢出桶。
当 map 中找不到可用的溢出桶时,runtime.newoverflow 会通过 newobject 新建溢出桶,此时正常桶和溢出桶在内存中的存储空间就不再连续了。
桶的结构体 runtime.bmap 在 Go 语言源代码中的定义只包含一个简单的tophash字段,它存储了键的哈希值的高 8 位。通过比较tophash可以减少访问键值对的次数以提高性能。
在运行期间,该结构体其实不止包含tophash字段,我们可以根据编译期间的 cmd/compile/internal/reflectdata.MapBucketType 函数重建它的结构:
1
2
3
4
5
6
| type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
overflow uintptr
}
|
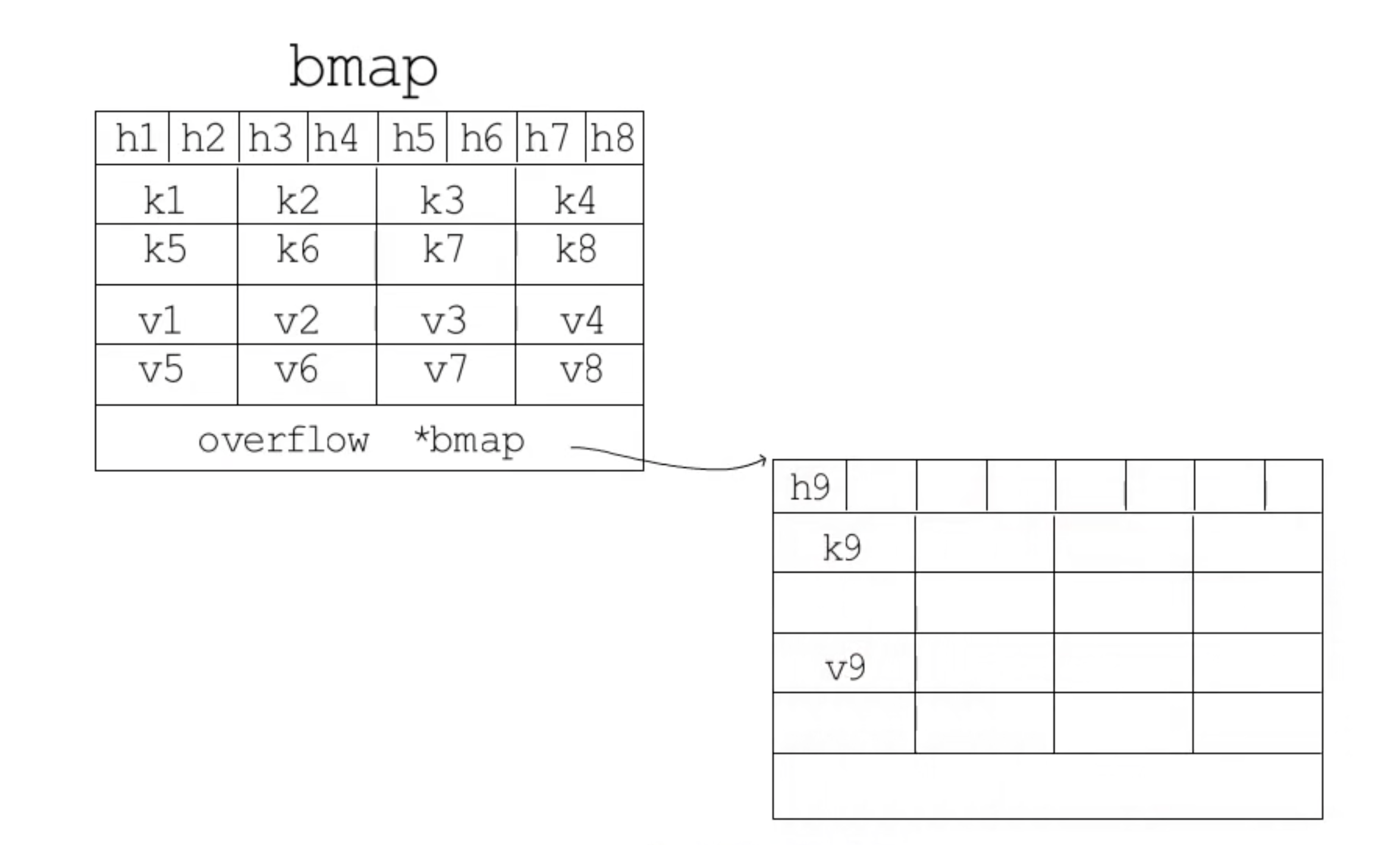
当哈希表中的元素数量少于或者等于 25 个时,编译器会将字面量初始化的结构体转换成以下的代码,将所有的键值对一次加入到哈希表中:
1
2
3
4
| hash := make(map[string]int, 3)
hash["1"] = 2
hash["3"] = 4
hash["5"] = 6
|
一旦哈希表中元素的数量超过了 25 个,编译器会创建两个数组分别存储键和值,这些键值对会通过如下所示的for循环加入哈希:
1
2
3
4
5
6
| hash := make(map[string]int, 26)
vstatk := []string{"1", "2", "3", ... , "26"}
vstatv := []int{1, 2, 3, ... , 26}
for i := 0; i < len(vstak); i++ {
hash[vstatk[i]] = vstatv[i]
}
|
无论使用哪种方法,使用字面量初始化的过程都会使用 Go 语言中的关键字make来创建新的哈希并通过最原始的[]语法向哈希追加元素。
当创建的哈希被分配到栈上并且其容量小于BUCKETSIZE = 8时,cmd/compile/internal/walk.walkMakeSlice 函数会在编译阶段快速初始化哈希,这是编译器对小容量的哈希所做的优化:
1
2
3
4
5
6
7
8
9
10
| var h *hmap
// Allocate hmap on stack
var hv hmap
h = &hv
if hint <= BUCKETSIZE {
var bv bmap
b := &bv
h.buckets = b
h.hash0 = rand32()
}
|
除此之外,所有初始化map的语句都会被转换成 runtime.makemap:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| func makemap(t *maptype, hint int, h *hmap) *hmap {
// 计算哈希占用的内存是否溢出或者超出能分配的最大值
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
if overflow || mem > maxAlloc {
hint = 0
}
if h == nil {
h = new(hmap)
}
// 获取一个随机的哈希种子
h.hash0 = uint32(rand())
B := uint8(0)
// 根据传入的 hint(make(map[k]v, hint))计算出至少需要的桶数量;
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
// 使用 runtime.makeBucketArray 创建用于保存桶的数组
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
|
runtime.makeBucketArray 会根据B计算出需要创建的桶数并在内存中分配一片连续的空间用于存储数据:
- 当桶的数量小于 $2^4$ 时,由于数据较少、使用溢出桶的可能性较低,会省略创建的过程以减少额外开销;
- 当桶的数量大于 $2^4$ 时,会额外创建 $2^{B-4}$ 个溢出桶。
v := hash[key] 操作会先被转化为 runtime.mapaccess1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
// map 不支持并发读写
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// 通过哈希函数和种子获取 key 对应的哈希值
hash := t.Hasher(key, uintptr(h.hash0))
// m 为桶掩码,等于 1<<B - 1
m := bucketMask(h.B)
// hash&m 为 key 所在桶的编号
// 通过指针计算目标桶的位置
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))
// 获取 key 对应的哈希值的高八位
top := tophash(hash)
bucketloop:
// 依次遍历正常桶和溢出桶中的数据
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
// 将 key 对应的哈希值的高八位与桶中存储的 tophash 进行比较
if b.tophash[i] != top {
// emptyRest = 0: this cell is empty,
// and there are no more non-empty cells at higher indexes or overflows.
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// 若 tophash 相等,则移动指针得到桶中存储的键 k
// 其中,dataOffset 是桶中第一个键相对于 bmap 起始地址的偏移量
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// 再将 key 与 k 进行比较,若相等则读取指向目标值的指针并返回
if t.Key.Equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.t.ValueSize))
return e
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
|
如下图所示,正是因为每个桶都是一片连续的内存空间,我们才能通过 runtime.add 操作指针以访问桶中存储的键。
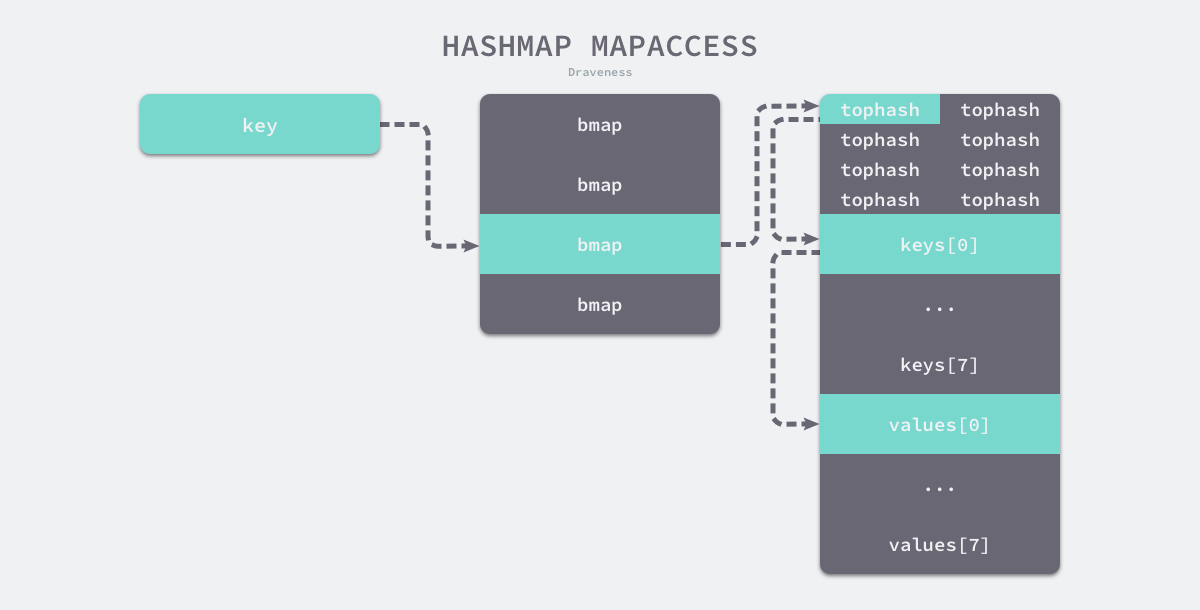
另外,选择桶序号时用的是键的哈希值的最低几位(hash&m),而加速访问用的是键的哈希值的高 8 位,这种设计能够减少同一个桶中有大量相等tophash的概率以免影响性能。
v, ok := hash[key]操作则会被转化为 runtime.mapaccess2,它在此基础之上多返回了一个标识键值对是否存在的布尔值。我们能够通过这个布尔值更准确地知道:当v == nil时,v 到底是哈希中存储的元素还是表示该键对应的元素不存在。因此我们在访问哈希表时更推荐使用这种方式判断元素是否存在。
hash[k] = v操作会在编译期间被转换成 runtime.mapassign,该函数需要兼顾以下三种情况:
k在桶中存在,返回v在桶中的地址;k在桶中不存在且桶中有空位,返回k和v应当插入的地址;k在桶中不存在且桶已满,对当前桶进行扩容然后再返回k和v应当插入的地址。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
| func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// 根据 key 计算哈希值
hash := t.hasher(key, uintptr(h.hash0))
again:
// 获取 key 所在的桶序号
bucket := hash & bucketMask(h.B)
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// 获取 key 对应的哈希值的高八位
top := tophash(hash)
var inserti *uint8 // key 的哈希值在 tophash 数组中的索引
var insertk unsafe.Pointer // key 插入的地址
var elem unsafe.Pointer // elem 插入的地址
bucketloop:
for {
// 遍历所有正常桶和溢出桶
for i := uintptr(0); i < bucketCnt; i++ {
// 将 key 对应的哈希值的高八位与桶中存储的 tophash 进行比较
if b.tophash[i] != top {
// 若不相等,则判断是否为空位
if isEmpty(b.tophash[i]) && inserti == nil {
// 若为空位,则将其标记为候选插入位置
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
// 若 tophash 均不匹配,则跳出内循环
continue
}
// 若 tophash 相等,则移动指针得到桶中存储的键 k
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// 再将 key 与 k 进行比较
if !t.Key.Equal(key, k) {
continue
}
// 通过指针移动得到值的地址并直接返回
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
goto done
}
// 遍历完正常桶后,将在下一个内循环中遍历溢出桶
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// inserti 为 nil,说明当前桶和溢出桶已满
if inserti == nil {
// 调用 runtime.newoverflow 创建新桶
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// 若 key 在哈希表中不存在,则为新键值对规划内存
// 间接存储 key(如大尺寸 key,存指针节省内存)
if t.indirectkey() {
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
// 间接存储 value(如大尺寸 value)
if t.indirectelem() {
vmem := newobject(t.Elem)
*(*unsafe.Pointer)(elem) = vmem
}
// 通过 runtime.typedmemmove 将 key 移动到 insertk 指向的内存空间
typedmemmove(t.Key, insertk, key)
*inserti = top
h.count++
done:
// 返回 key 对应的 elem 地址
return elem
}
|
由此可见,runtime.mapassign 并不会将值复制到桶中,真正的赋值操作是在编译期间插入的:
1
2
3
4
| 00018 (+5) CALL runtime.mapassign_fast64(SB)
00020 (5) MOVQ 24(SP), DI ;; DI = &value
00026 (5) LEAQ go.string."88"(SB), AX ;; AX = &"88"
00027 (5) MOVQ AX, (DI) ;; *DI = AX
|
runtime.mapassign_fast64 与 runtime.mapassign 函数的逻辑差不多,我们需要关注的是后面的三行代码。其中24(SP)是该函数返回值的地址,我们通过LEAQ指令将字符串的地址存储到寄存器AX中,MOVQ 指令将字符串"88"存储到了目标地址上从而完成了这次哈希的写入。
上一节在介绍mapassign时其实省略了其中的扩容操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
| func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
// 哈希的扩容不是一个原子的过程,需要判断当前是否处于扩容状态
// 判断 h.growing() 返回的 oldbuckets 是否非空
// 若 oldbuckets 非空,则说明正在扩容
// 装载因子超过 6.5 或溢出桶过多时触发扩容 hashgrow
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
// Growing the table invalidates everything, so try again
goto again
}
...
}
|
我们可以发现有以下两种情况将触发扩容:
- 装载因子超过 6.5:哈希的空间使用率过高,哈希冲突的概率较大;
- 溢出桶过多:如果我们持续向哈希中插入数据并将它们全部删除,那么即使哈希表中的装载因子没有超过阈值,溢出桶的数量也会越来越多从而造成缓慢的 内存泄漏。
runtime.hashGrow 会根据具体情况采取不同的扩容策略:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
// 若装载因子未超过阈值,则说明溢出桶过多触发了扩容
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
// 扩容规则将是 sameSizeGrow,即等量扩容,h.B 不变
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
// 创建一组新桶和预创建的溢出桶
// 若装载因子超过阈值,h.b 加一,桶的数量翻倍
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
h.B += bigger
h.flags = flags
// 将 oldbucket 设为原有的桶
h.oldbuckets = oldbuckets
// 将 bucket 设为新的新的空桶
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// 更新新桶的溢出桶相关字段
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
|
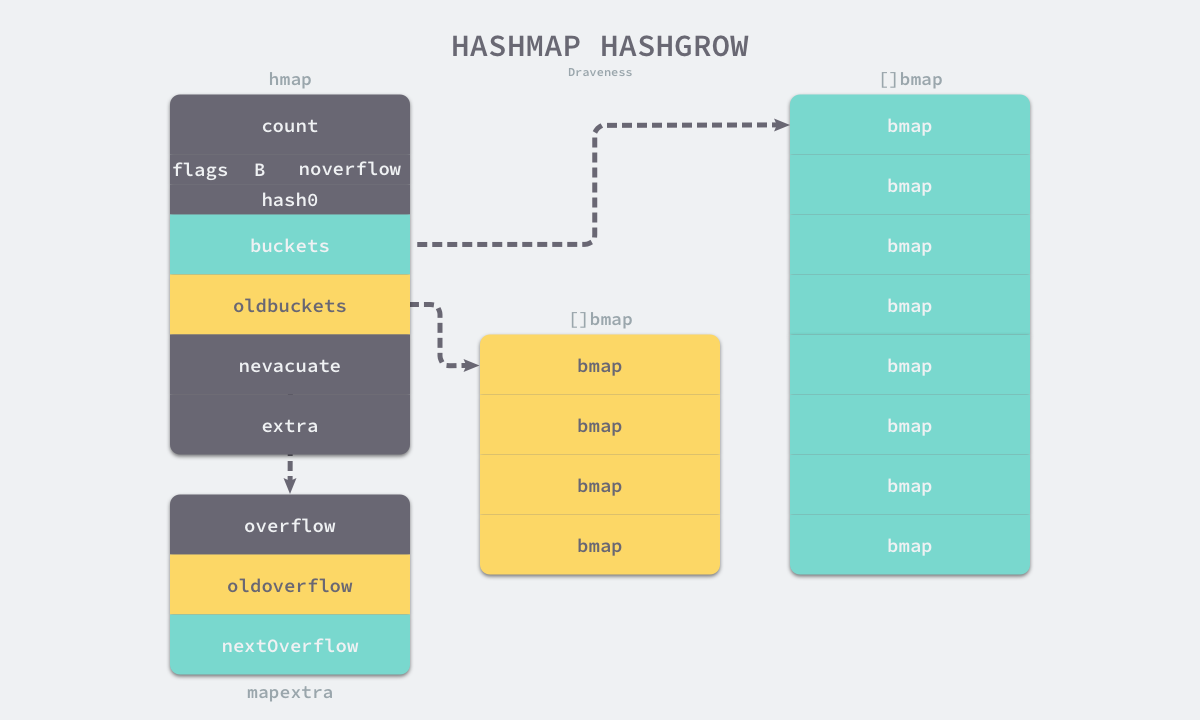
我们可以看出,等量扩容创建的新桶数量和旧桶一样,而增量扩容创建的新桶则为原来的两倍。hashGrow只是创建了新桶,并没有对数据进行复制和转移。数据迁移是在后续对哈希表进行写入或删除操作时由 runtime.growWork 和 runtime.evacuate 共同完成的,后者会对桶中的元素分流:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
| func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
// 计算要迁移的旧桶 b 的地址,oldbucket 是其索引
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// 计算扩容前桶的数量
newbit := h.noldbuckets()
// 若 b 没有被迁移
if !evacuated(b) {
// 创建两个 evacDst 结构体用于保存分配上下文
// 它们分别指向一个新桶
var xy [2]evacDst
x := &xy[0]
// 迁移到 x 的桶序号不变
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
if !h.sameSizeGrow() {
// 只有在翻倍扩容的情况下才计算 y
y := &xy[1]
// 迁移到 y 的桶序号增加扩容前桶的数量
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}
// 遍历所有的正常桶和溢出桶
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// // 遍历桶 b 中的所有元素
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// 若为空位,则标记为 evacuatedEmpty: cell is empty, bucket is evacuated
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
k2 := k
var useY uint8
if !h.sameSizeGrow() {
// 计算哈希值确定该元素应当迁移到 x 指向的桶还是 y 指向的桶
hash := t.Hasher(k2, uintptr(h.hash0))
// k2 为特殊值(NaN)时的处理
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {.
useY = top & 1
top = tophash(hash)
} else {
// 常规情况下的处理
if hash&newbit != 0 {
// 元素应当迁移到 y 指向的桶
useY = 1
}
}
}
...
// 更新 tophash 以标记元素已被迁移到 x 指向的桶还是 y 指向的桶
b.tophash[i] = evacuatedX + useY
// 确定元素最终的迁移位置
dst := &xy[useY]
// 若新桶已满,则创建溢出桶
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
// 复制键值对到新 bucket
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.Key, dst.k, k) // copy elem
}
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// 更新目标桶 x 或 y 的索引和键值对地址
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}
...
}
// 若当前迁移的桶正是 nevacuate 所记录的,则更新迁移进度
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
|
举例来说,旧桶数量是 4,新桶数量是 8,newbit为 二进制 100。那么旧桶中 3 号桶的元素就会被分流到新桶中的 3 号桶(键哈希值倒数第三位为 0,如 011 & 100 = 000 == 0)和 7 号桶(键哈希值倒数第三位为 1,如 111 & 100 = 100 != 0):
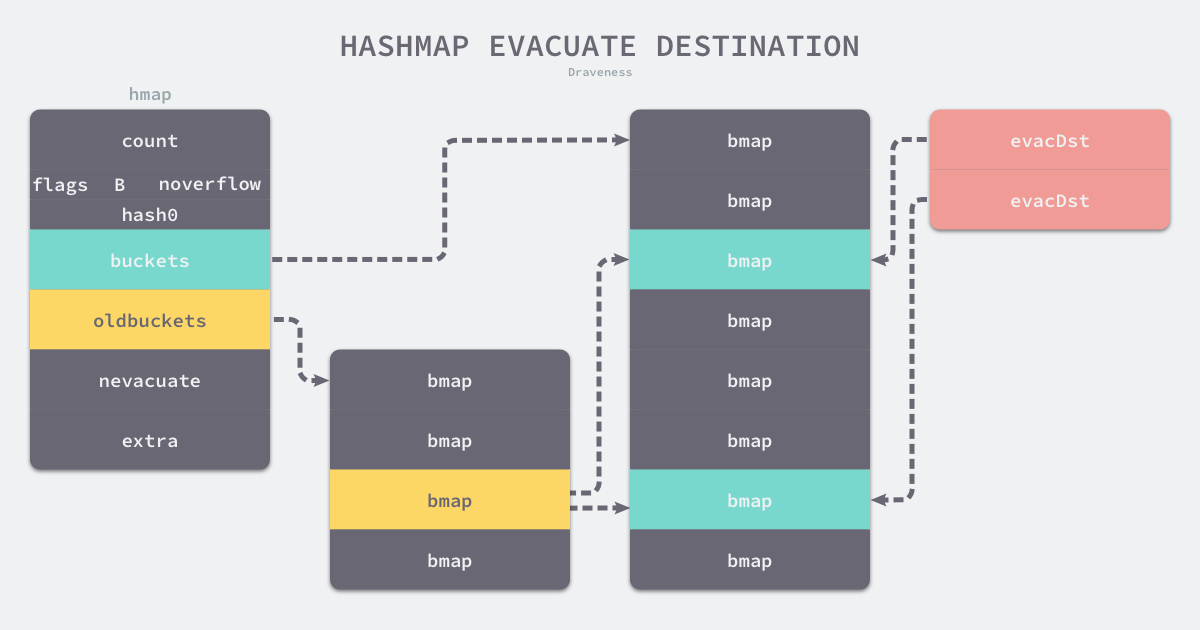
之前在分析访问哈希表时其实省略了扩容期间获取键值对的逻辑,当哈希表的oldbuckets存在时,会先定位到旧桶并在该桶没有被迁移时从中获取键值对。
而当哈希表正在处于扩容状态时,只有向哈希表写入或删除时才会触发 runtime.growWork 增量复制哈希表中的内容。先迁移旧桶,再完成写入:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
...
}
func growWork(t *maptype, h *hmap, bucket uintptr) {
// evacuate 将旧桶中的元素迁移到扩容后的新桶
evacuate(t, h, bucket&h.oldbucketmask())
// 如果已处于扩容阶段,则再迁移第一个未迁移的旧桶
// 防止某些旧桶没有被写入导致扩容长时间无法完成
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
|
传入该函数的bucket参数是我们即将访问的某一个新桶,bucket&h.oldbucketmask()是与之对应的旧桶地址。举例来说,旧桶数量是 4,新桶数量是 8,旧桶的掩码是 $11_2$。如果bucket指向新桶中的 5 号桶,那么它在旧桶中的序号就应当是 $0101_2 \And 0011_2$,即 1 号。该函数仅操作单个桶而非整个bmap数组,因此 Go 语言中哈希的扩容是渐进式的,每次最多迁移两个桶。
delete关键字可以删除哈希表中某一个键对应的元素,它会在编译时被转换为 runtime.mapdelete 函数簇中的一个。用于处理删除逻辑的函数与 runtime.mapassign 几乎完全相同,不太需要刻意关注。
Go 语言中的字符串是一个只读的字节数组:

不过我们仍然可以通过在string和[]byte类型之间反复转换实现修改这一目的:
- 先将这段内存复制到堆或者栈上;
- 将变量的类型转换成
[]byte后并修改字节数据; - 将修改后的字节数组转换回
string;
使用双引号声明的字符串只能用于单行字符串的初始化,如果字符串内部出现双引号,则需要使用\符号避免编译器的解析错误。而反引号声明的字符串可以摆脱单行的限制,并且可以在字符串内部直接使用",在遇到需要手写 JSON 或者其他复杂数据格式的场景下非常方便:
1
2
3
4
| str1 := "this is a string"
str2 := `this is another
string`
json := `{"author": "draven", "tags": ["golang"]}`
|
每一个字符串在运行时都会使用如下的 internal/unsafeheader.String 表示,其中包含指向字节数组的指针和数组的大小:
1
2
3
4
| type String struct {
Data unsafe.Pointer
Len int
}
|
因此我们常说字符串是只读的切片类型,所有在字符串上的写入操作都是通过复制实现的。
正常情况下,运行时会调用copy将输入的多个字符串复制到目标字符串所在的内存空间。新的字符串是一片新的内存空间,与原来的字符串也没有任何关联,一旦需要拼接的字符串非常大,复制带来的性能损失是无法忽略的。
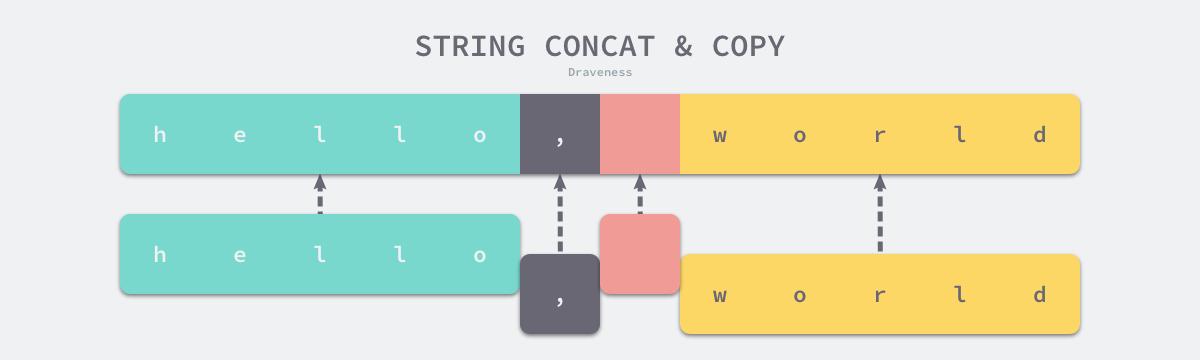
如果需要拼接多次,应使用strings.Builder,最小化内存复制次数。
从字节数组[]byte到字符串的转换需要使用 runtime.slicebytetostring 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| // ptr 是指向切片第一个元素的指针
// n 是切片的长度,buf 是用于保存结果的固定长度缓冲区
func slicebytetostring(buf *tmpBuf, ptr *byte, n int) string {
if n == 0 {
return ""
}
...
if n == 1 {
p := unsafe.Pointer(&staticuint64s[*ptr])
// unfase.String 根据传入的指针和长度
// 返回实际的 string
return unsafe.String((*byte)(p), 1)
}
var p unsafe.Pointer
// 根据缓冲区大小决定是否需要为新字符串分配一片内存空间
if buf != nil && n <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(n), nil, false)
}
// 将字节数组中的元素复制到新的内存空间中
memmove(p, unsafe.Pointer(ptr), uintptr(n))
return unsafe.String((*byte)(p), n)
}
|
当我们想要将字符串转换成[]byte类型时,需要使用 runtime.stringtoslicebyte 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
// 传入缓冲区时,用缓冲区存储字节切片
b = buf[:len(s)]
} else {
// 无缓冲区时,创建新的字节切片
b = rawbyteslice(len(s))
}
// 将字符串中的内容复制到字节切片
copy(b, s)
return b
}
|
因此不过无论从哪种类型转换到另一种都需要复制数据,而内存复制的性能损耗会随着字符串和[]byte长度的增长而增长。