原书中的代码片段基于 Go 1.15,笔记则根据 Go 1.22 版本的更新进行了相应替换。
抽象语法树(Abstract Syntax Tree,AST),是源代码语法的结构的一种抽象表示。它用树状的方式表示编程语言的语法结构,每个节点都表示源代码中的一个元素,每一颗子树都表示一个语法元素。以下列代码为例:
1
2
3
4
5
6
| while b ≠ 0:
if a > b:
a := a - b
else:
b := b - a
return a
|
编译器的语法分析阶段会生成如下图所示的抽象语法树:

抽象语法树抹去了源代码中不重要的一些字符——空格、分号或者括号等等。编译器在执行完语法分析之后会输出一个抽象语法树,这个抽象语法树会辅助编译器进行语义分析,我们可以用它来确定语法正确的程序是否存在一些类型不匹配的问题。
静态单赋值(Static Single Assignment,SSA)是中间代码(IR)的一种特性,即每个变量只会被赋值一次。在实践中,我们通常会用下标实现静态单赋值。下列代码中第一行的赋值语句显然没有起到任何作用:
1
2
3
| x := 1
x := 2
y := x
|
但对于编译器来说,必须执行一定分析才能确定这一点。而如果中间代码具备 SSA 特性:
1
2
3
| x_1 := 1
x_2 := 2
y_1 := x_2
|
编译器便可以清楚地发现x_1和y_1没有任何关系,它在生成机器码时就可以省去x := 1的赋值,从而通过减少需要执行的指令来优化这段代码。
编译器前端负责将源代码翻译成与编程语言无关的中间代码,后端主要负责目标代码的生成和优化。因为 SSA 的主要作用是对代码进行优化,所以它是编译器后端的一部分。
- 复杂指令集:通过增加指令的类型,减少需要执行的指令数量;
- 精简指令集:通过更少的指令类型完成计算任务。
原图链接:Understanding Go Compiler
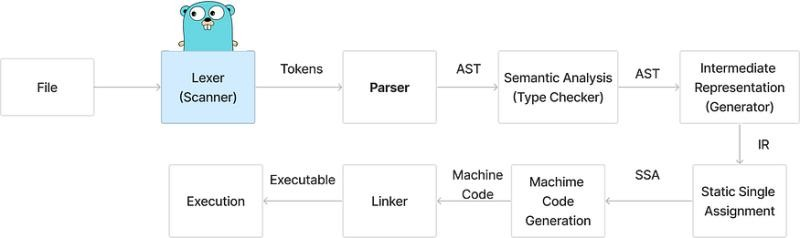
词法分析的作用是解析源代码文件,它将文件中的字符串序列转换成 Token 序列(即分词),如package,json,import, ……,方便后面的处理和解析。我们一般会把执行词法分析的程序称为词法解析器(Lexer)。
从 Go 语言中定义的 Token 类型,我们可以将元素分成几个不同的类别,分别是名称、字面量、操作符、分隔符和关键字。词法分析主要由 cmd/compile/internal/syntax.scanner 结构体的 next 方法驱动,该结构体会持有当前被扫描到的 Token,而该函数的主体则是一个switch/case结构。
语法分析器则会将词法分析器输出的 Token 序列按照编程语言规定好的文法(Grammar)归纳成一个 SourceFile 结构,即抽象语法树:
1
2
3
4
5
6
7
| "json.go": SourceFile {
PackageName: "json",
ImportDecl: []Import{
"io",
},
TopLevelDecl: ...
}
|
该树的根节点 cmd/compile/internal/syntax.File 包含了当前文件所属的包名、定义的常量、结构体和函数等:
1
2
3
4
5
6
7
| type File struct {
Pragma Pragma
PkgName *Name
DeclList []Decl
Lines uint
node
}
|
其他节点的结构体则在 cmd/compile/internal/syntax/nodes.go 文件中定义,其中包含了全部声明类型,如函数声明:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| type (
Decl interface {
Node
aDecl()
}
...
FuncDecl struct {
Attr map[string]bool
Recv *Field // 接收者
Name *Name // 函数名
Type *FuncType // 函数类型
Body *BlockStmt // 函数体
Pragma Pragma
decl
}
)
|
编译器遍历抽象语法树以保证节点不存在类型错误,所有的类型错误和不匹配都会在这一个阶段被暴露出来(强类型),包括结构体对接口的实现。
Go 语言的编译器不仅使用静态类型检查来保证程序运行的类型安全,还会在编译期间引入类型信息,让工程师能够使用反射来判断参数和变量的类型。当我们想要将interface{}转换成具体类型时会进行动态类型检查,如果无法发生转换程序就会崩溃。
编译器类型检查的主要逻辑都在 cmd/compile/internal/typecheck.typecheck 和 cmd/compile/internal/typecheck.typecheck1 中,后者是类型检查的核心。该函数根据传入 节点 的操作类型进入不同分支:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| func typecheck1(n ir.Node, top int) ir.Node {
switch n.Op {
...
// type or expr
case ir.ODEREF:
n := n.(*ir.StarExpr)
return tcStar(n, top)
...
case ir.OMAKE:
n := n.(*ir.CallExpr)
return tcMake(n)
case ir.ONEW:
n := n.(*ir.UnaryExpr)
return tcNew(n)
...
}
}
|
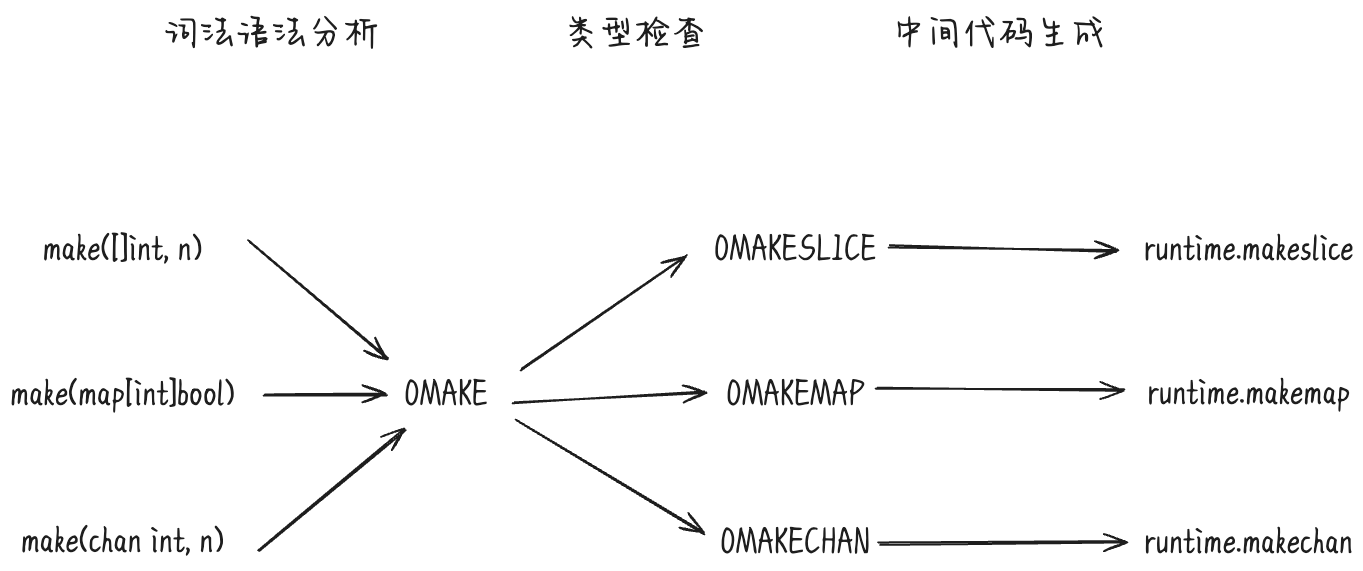
以OMAKE节点为例,cmd/compile/internal/typecheck.tcMake 会对传入make的参数进行合法性检查,并根据第一个参数修改节点的操作类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| func tcMake(n *ir.CallExpr) ir.Node {
args := n.Args
if len(args) == 0 {
base.Errorf("missing argument to make")
n.SetType(nil)
return n
}
n.Args = nil
l := args[0]
l = typecheck(l, ctxType)
t := l.Type()
if t == nil {
n.SetType(nil)
return n
}
// i 代表参数的最小个数
i := 1
var nn ir.Node
switch t.Kind() {
...
case types.TSLICE:
...
// 节点的操作类型变为 OMAKESLICE
nn = ir.NewMakeExpr(n.Pos(), ir.OMAKESLICE, l, r)
case types.TMAP:
...
// 节点的操作类型变为 OMAKEMAP
nn = ir.NewMakeExpr(n.Pos(), ir.OMAKEMAP, l, nil)
case types.TCHAN:
...
// 节点的操作类型变为 OMAKECHAN
nn = ir.NewMakeExpr(n.Pos(), ir.OMAKECHAN, l, nil)
}
if i < len(args) {
base.Errorf("too many arguments to make(%v)", t)
n.SetType(nil)
return n
}
nn.SetType(t)
return nn
}
|
在编译过程中,编译器会在将源代码转换到机器码的过程中,先把源代码转换成一种中间的表示形式,即 中间代码。很多编译器需要将源代码翻译成多种机器码,而直接翻译高级编程语言相对比较困难。中间代码是一种更接近机器语言的表示形式,对它的优化和分析相比直接分析高级编程语言更容易。
编译阶段入口的主函数 cmd/compile/internal/gc.Main 中关于中间代码生成的部分如下,主要分为配置初始化和编译函数两部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| func Main(archInit func(*ssagen.ArchInfo)) {
...
// Prepare for backend processing.
ssagen.InitConfig()
...
// The SSA backend supports using multiple goroutines,
// so keep it as late as possible to maximize
// how much work we can batch and process concurrently.
if len(compilequeue) != 0 {
compileFunctions()
continue
}
}
|
cmd/compile/internal/ssagen.InitConfig 的执行过程可以分为三个部分,首先便是创建结构体并缓存类型信息:
1
2
3
4
5
6
7
8
9
10
11
12
| func InitConfig() {
// ssa.types 存储了 Go 所有基本类型对应的指针
types_ := ssa.NewTypes()
// types.NewPtr 根据类型生成指向对应类型的指针
// 同时根据编译器的配置将生成的指针类型缓存在当前类型中
// 从而优化类型指针的获取效率
_ = types.NewPtr(types.Types[types.TINTER]) // *interface{}
_ = types.NewPtr(types.NewPtr(types.Types[types.TSTRING]))
_ = types.NewPtr(types.NewSlice(types.Types[types.TINTER]))
...
_ = types.NewPtr(types.ErrorType) // *error
|
该函数随后根据当前的 CPU 架构、类型结构体和上下文信息设置用于生成中间代码和机器码的函数。所有的配置一旦被创建,在整个编译期间就变为只读的且被中间代码生成和机器码生成阶段共享:
1
2
3
4
| // ssa.NewConfig 返回一个 ssa.Config 结构体
// 后者包含了用于生成中间代码和机器码的函数以及
// 编译器使用的指针、寄存器大小、可用寄存器列表等编译选项:
ssaConfig = ssa.NewConfig(base.Ctxt.Arch.Name, *types_, base.Ctxt, base.Flag.N == 0, Arch.SoftFloat)
|
最后,该函数会初始化一些编译器可能用到的 Go 语言运行时的函数:
1
2
3
4
5
6
7
8
| // Set up some runtime functions we'll need to call
...
// LookupRuntimeFunc looks up Go function name in package runtime
// 表示该方法已经注册到运行时包中
ir.Syms.Growslice = typecheck.LookupRuntimeFunc("growslice")
ir.Syms.Memmove = typecheck.LookupRuntimeFunc("memmove")
ir.Syms.Newobject = typecheck.LookupRuntimeFunc("newobject")
...
|
在生成中间代码之前,编译器还需要替换抽象语法树中节点的一些元素,这是通过 cmd/compile/internal/walk 包中的相关函数实现的:
1
2
3
4
5
6
7
| func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {}
func walkAppend(n *ir.CallExpr, init *ir.Nodes, dst ir.Node) ir.Node {}
func walkMakeMap(n *ir.MakeExpr, init *ir.Nodes) ir.Node {}
func walkMakeSlice(n *ir.MakeExpr, init *ir.Nodes) ir.Node {}
func walkSelect(sel *ir.SelectStmt) {}
func walkSwitch(sw *ir.SwitchStmt) {}
...
|
它们会将一些关键字和内建函数转换成运行时包中的函数调用:
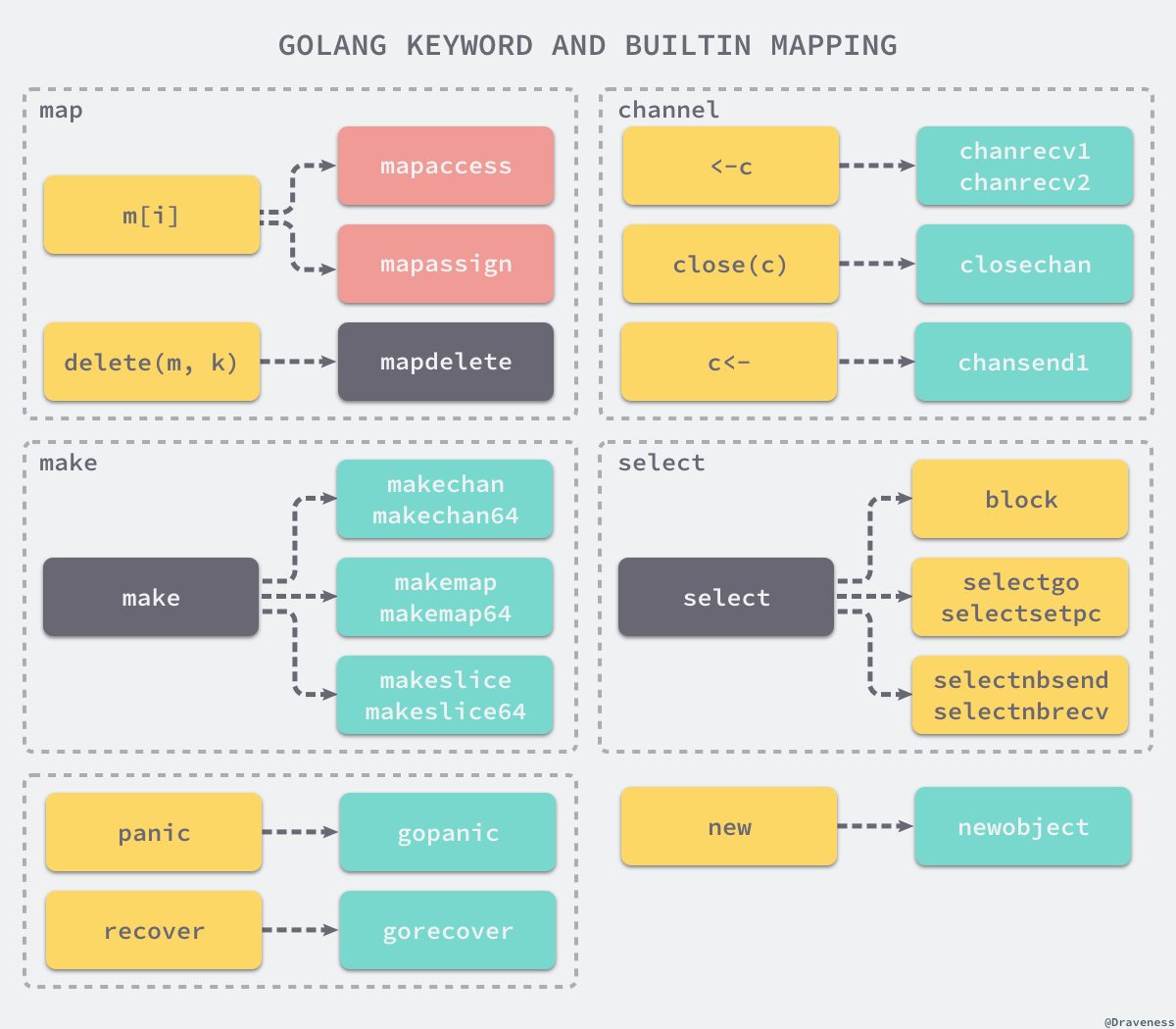
因此,关键字和内置函数的功能是由编译器和运行时共同完成的:
经过walk系列函数的处理之后,抽象语法树就不会再改变了。改写后的语法树会经过多轮处理(去掉无用代码并精简操作数)转变成最后的 SSA 中间代码,我们可以通过如下命令生成main.go的中间代码ssa.html:
1
2
3
4
5
| $ GOSSAFUNC=main go build main.go
# runtime
dumped SSA to /usr/local/Cellar/go/1.14.2_1/libexec/src/runtime/ssa.html
# command-line-arguments
dumped SSA to ./ssa.html
|
Go 语言源代码的 cmd/compile/internal 目录中包含了很多机器码生成相关的包,不同类型的 CPU 分别使用了不同的包生成机器码,其中包括 amd64、arm、arm64、mips、mips64、ppc64、s390x、x86 和 wasm。
机器码的生成主要由两部分协同完成:
- SSA 降级:将中间代码降级为汇编代码;
- 汇编器:将汇编代码翻译为机器码。