原书中的代码片段基于 Go 1.15,笔记则根据 Go 1.22 版本的更新进行了相应替换。
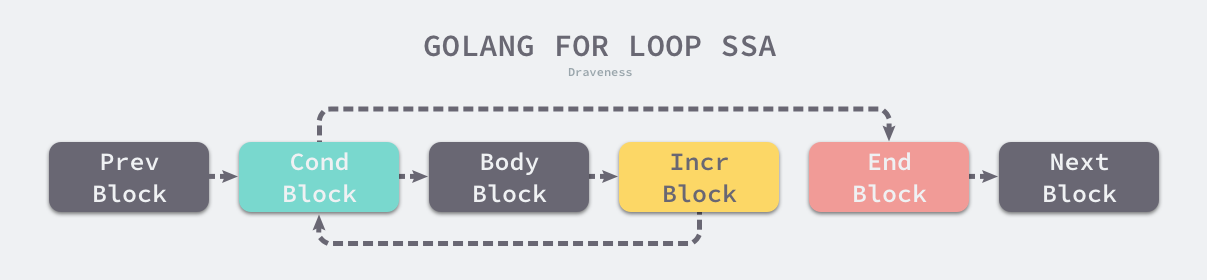
Go 语言中的经典循环在编译器看来是一个OFOR类型的节点,这个节点由以下四个部分组成:
- 初始化循环的
Ninit; - 循环的继续条件
Left; - 循环体结束时执行的
Right; - 循环体
NBody:
1
2
3
| for Ninit; Left; Right {
NBody
}
|
在生成 SSA 中间代码 的阶段,cmd/compile/internal/ssagen.stmt 会将循环中的代码分成不同的块:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| // stmt converts the statement n to SSA and adds it to s.
func (s *state) stmt(n ir.Node) {
...
switch n.Op() {
...
case ir.OFOR:
// OFOR: for Ninit; Left; Right { Nbody }
// cond (Left); body (Nbody); incr (Right)
n := n.(*ir.ForStmt)
base.Assert(!n.DistinctVars)
bCond := s.f.NewBlock(ssa.BlockPlain)
bBody := s.f.NewBlock(ssa.BlockPlain)
bIncr := s.f.NewBlock(ssa.BlockPlain)
bEnd := s.f.NewBlock(ssa.BlockPlain)
...
}
}
|
这些代码块之间的连接表示汇编语言中的跳转关系,与我们理解的for循环控制结构没有太多的差别:
除了使用经典的三段式循环之外,Go 语言还引入了另一个关键字range帮助我们快速遍历数组、切片、哈希表以及管道等集合类型。编译器会在编译期间将所有 for-range 循环变成普通 for 循环,即将ORANGE类型的节点转换成OFOR节点。我们将按照元素类型依次介绍遍历数组和切片、哈希表、字符串以及管道的过程。
对于数组和切片来说,Go 语言有三种不同的遍历方式,分别对应着代码中的不同条件。它们会在 cmd/compile/internal/walk.walkRange 函数中转换成不同的控制逻辑:
- 遍历数组和切片清空元素的情况;
- 使用
for range a {}遍历数组和切片; - 使用
for i := range a {}遍历数组和切片; - 使用
for i, elem := range a {}遍历数组和切片;
相比于依次清除数组或者切片中的数据,Go 语言会直接使用 runtime.memclrNoHeapPointers 或者 runtime.memclrHasPointers 清除目标数组内存空间中的全部数据,并在执行完成后更新遍历数组的索引:
1
2
3
4
5
6
7
8
9
10
11
12
| // 原代码
for i := range a {
a[i] = zero
}
// 优化后
if len(a) != 0 {
hp = &a[0]
hn = len(a)*sizeof(elem(a))
memclrNoHeapPointers(hp, hn)
i = len(a) - 1
}
|
调用者不关心数组a的索引和元素,循环会被编译器转换成如下形式:
1
2
3
4
5
6
| ha := a
hv1 := 0
hn := len(ha)
for ; hv1 < hn; hv1++ {
...
}
|
调用者不关心数组的元素,只关心遍历数组使用的索引。循环会被编译器转换成如下形式:
1
2
3
4
5
6
7
8
| ha := a
hv1 := 0
hn := len(ha)
for ; hv1 < hn; hv1++ {
// 传递遍历数组时的索引
v1 := hv1
...
}
|
调用者同时关心数组的索引和切片,循环会被编译器转换成如下形式:
1
2
3
4
5
6
7
8
| ha := a
hv1 := 0
hn := len(ha)
for ; hv1 < hn; hv1++ {
// 变量在循环内部定义
v1, v2 := hv1, ha[hv1]
...
}
|
对于所有的 for-range 循环,Go 语言都会在编译期将原切片或者数组赋值给一个新变量ha,在赋值的过程中发生了拷贝。而我们又通过len关键字预先获取了切片的长度,所以在循环中追加新的元素并不会改变循环执行的次数:
1
2
3
4
5
6
7
8
9
10
11
| func main() {
arr := []int{1, 2, 3}
for _, v := range arr {
arr = append(arr, v)
}
fmt.Println(arr)
}
// 循环不会永动
$ go run main.go
1 2 3 1 2 3
|
另外,之前版本的 Go 语言会在循环外部定义变量v2,每次迭代v2的地址均不变,因此会出现如下 Bug:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for _, v := range arr {
fmt.Printf("origin addr: %p value: %v\n", &v, v)
// newArr = append(newArr, &arr[i])
newArr = append(newArr, &v)
}
for _, v := range newArr {
fmt.Printf("addr: %p value: %v\n", v, *v)
}
}
// go 1.21
$ go run main.go
origin addr: 0xc0000a0000 value: 1
origin addr: 0xc0000a0000 value: 2
origin addr: 0xc0000a0000 value: 3
addr: 0xc0000a0000 value: 3
addr: 0xc0000a0000 value: 3
addr: 0xc0000a0000 value: 3
|
Go 语言在 1.22 版本修改了控制结构的执行语义,短声明定义的循环变量将在每次迭代重新定义,详见:Proposal: Less Error-Prone Loop Variable Scoping。因此执行上述代码会输出我们期望得到的结果:
1
2
3
4
5
6
7
8
| // go 1.22
$ go run main.go
origin addr: 0xc000012028 value: 1
origin addr: 0xc000012060 value: 2
origin addr: 0xc000012068 value: 3
addr: 0xc000012028 value: 1
addr: 0xc000012060 value: 2
addr: 0xc000012068 value: 3
|
runtime.hiter 是 Go 语言内部用于哈希表迭代的结构体:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| type hiter struct {
key unsafe.Pointer // 指向当前迭代的键,nil 代表迭代结束
elem unsafe.Pointer // 指向当前迭代的值
t *maptype // 指向当前 map 的类型信息
h *hmap // 指向当前正在迭代的 map
buckets unsafe.Pointer // 指向迭代初始化时的桶
bptr *bmap // 指向当前迭代的桶
overflow *[]*bmap
oldoverflow *[]*bmap
startBucket uintptr
offset uint8
wrapped bool
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}
|
在遍历哈希表时,编译器会使用 runtime.mapiterinit 和 runtime.mapiternext 重写原始的 for-range 循环。前者首先初始化 runtime.hiter 结构体中的字段并保存当前桶的状态,然后随机选择一个桶作为遍历的起始位置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| func mapiterinit(t *maptype, h *hmap, it *hiter) {
it.t = t
it.h = h
// grab snapshot of bucket state
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}
// decide where to start
r := uintptr(rand())
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// iterator state
it.bucket = it.startBucket
mapiternext(it)
}
|
runtime.mapiternext 函数的执行主要分为桶的选择和桶内元素遍历两部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| func mapiternext(it *hiter) {
h := it.h
t := it.t
bucket := it.bucket
// b 指向待遍历的桶
b := it.bptr
i := it.i
checkBucket := it.checkBucket
next:
if b == nil {
if bucket == it.startBucket && it.wrapped {
// 当不存在待遍历的桶时,结束迭代
it.key = nil
it.elem = nil
return
}
if h.growing() && it.B == h.B {
// 哈希表正在扩容中,处理扩容逻辑
...
} else {
// 待遍历的桶为空时,计算需要遍历的新桶地址
b = (*bmap)(add(it.buckets, bucket*uintptr(t.BucketSize)))
checkBucket = noCheck
}
bucket++
if bucket == bucketShift(it.B) {
bucket = 0
it.wrapped = true
}
i = 0
}
for ; i < bucketCnt; i++ {
offi := (i + it.offset) & (bucketCnt - 1)
// 根据偏移量计算桶内键值对指针
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
if checkBucket != noCheck && !h.sameSizeGrow() {
// 哈希表正在增量扩容中,处理扩容逻辑
...
}
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
// 目标元素未迁移,k 和 e 为准确数据,可以直接返回
it.key = k
it.elem = e
} else {
// 目标元素已迁移,需要通过 runtime.mapaccessK 获取键值对
rk, re := mapaccessK(t, h, k)
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
it.checkBucket = checkBucket
return
}
// 如果当前桶已迭代完成,继续迭代溢出桶
b = b.overflow(t)
i = 0
goto next
}
|
由此可见,哈希表的遍历过程为:首先随机选出一个正常桶开始遍历,然后遍历其所有的溢出桶,最后按照索引顺序遍历其他的正常桶和溢出桶,直到全部桶遍历完成。
哈希表遍历的随机性也会导致一些奇怪现象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| func main() {
var m = map[string]int{
"A": 21,
"B": 22,
"C": 23,
}
counter := 0
for k, v := range m {
if counter == 0 {
m["D"] = 20
}
counter++
fmt.Println(k, v)
}
fmt.Println(counter)
}
// 可能的结果
$ go run main.go
B 22
A 21
C 23
3
|
多次执行上述代码可能出现counter为 3 且输出结果不包含D的情况。这是因为遍历开始时随机选择的桶为空桶,而D又恰好插入了该桶。
字符串的遍历过程与数组、切片和哈希表非常相似,只是会将字符串中的字节转换成rune类型。for i, r := range s {}的结构会被转换成如下所示的形式:
1
2
3
4
5
6
7
8
9
10
11
12
13
| ha := s
for hv1 := 0; hv1 < len(ha); {
hv1t := hv1
hv2 := rune(ha[hv1])
// 当前字节是常规 ASCII 码,只占用一个字节长度
if hv2 < utf8.RuneSelf {
hv1++
} else {
// 占用多个字节,使用 runtime.decoderune 解码
hv2, hv1 = decoderune(ha, hv1)
}
v1, v2 := hv1t, hv2
}
|
使用range遍历管道也是比较常见的做法,一个形如for v := range ch {}的语句最终会被转换成如下的格式:
1
2
3
4
5
6
7
8
9
10
11
| ha := a
// 从管道中取出等待处理的值并阻塞当前协程
hv1, hb := <-ha
// 若当前值不存在,则管道已被关闭
for ; hb != false; hv1, hb = <-ha {
// 若当前值存在,将其赋给 v1
v1 := hv1
// 清除 hv1 中的数据,重新陷入阻塞等待新数据
hv1 = nil
...
}
|
这里的代码可能与编译器生成的稍微有一些出入,但是结构和效果是完全相同的。
C 语言中的系统调用 select 可以同时监听多个文件描述符的可读或者可写的状态,而 Go 语言中的select关键字也能让 Goroutine 同时等待多个管道可读或者可写。
select是与switch相似的控制结构,但与后者不同的是,前者中的case表达式必须是管道的收发操作。当select中的两个case同时触发时,会随机执行其中一个以避免饥饿问题的出现。
Go 语言的源代码中没有select对应的结构体,但其控制结构中的case关键字是由 runtime.scase 结构体表示的:
1
2
3
4
| type scase struct {
c *hchan // chan
elem unsafe.Pointer // data element
}
|
非default的case都与管道的发送和接收有关,因此该结构体中也包含了一个 runtime.hchan 类型的字段存储case中使用的管道。
编译器在中间代码生成期间会根据以下四种情况对控制语句进行优化:
select不存在任何的case;select只存在一个case;select存在两个case,其中一个case是default;select存在多个case;
上述过程均发生在 cmd/compile/internal/walk.walkSelectCases 函数中。
如果select中不存在任何case:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| func walkSelectCases(cases []*ir.CommClause) []ir.Node {
ncas := len(cases)
if ncas == 0 {
// mkcallstmt 调用 runtime.block 函数
return []ir.Node{mkcallstmt("block")}
}
...
}
func block() {
// 当前 Goroutine 让出对处理器的使用权
// 传入等待原因 waitReasonSelectNoCases
gopark(nil, nil, waitReasonSelectNoCases, traceBlockForever, 1)
}
|
因此,空的select语句会直接阻塞当前 Goroutine,导致其进入无法被唤醒的永久休眠状态。
如果当前select中只包含一个 case,那么编译器会将其改写为:
1
2
3
4
5
6
7
8
9
10
11
12
13
| // 改写前
select {
case v, ok <-ch: // case ch <- v
...
}
// 改写后
if ch == nil {
// 若 case 中的 ch 为空,当前 Goroutine 会被挂起并陷入永久休眠
block()
}
v, ok := <-ch // case ch <- v
...
|
当select中仅包含两个 case,并且其中一个是 default 时,Go 语言的编译器就会认为这是一次非阻塞的收发操作。cmd/compile/internal/walk.walkSelectCases 会对这种情况单独处理。
当case中表达式的类型是OSEND时,编译器会使用条件语句和 runtime.selectnbsend 函数改写代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 改写前
select {
case ch <- v:
... foo
default:
... bar
}
// 改写后
if selectnbsend(ch, v) {
... foo
} else {
... bar
}
|
runtime.selectnbsend 向 runtime.chansend 函数传入的block参数为false,因此当无缓冲管道不存在等待的接收者或有缓冲管道的缓冲区空间不足时,当前 Goroutine 不会被阻塞而是直接返回。详见:发送数据。
1
2
3
| func selectnbsend(c *hchan, elem unsafe.Pointer) (selected bool) {
return chansend(c, elem, false, getcallerpc())
}
|
当case中表达式的类型是OSELRECV2时,编译器会使用条件语句和 runtime.selectnbrecv 函数改写代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 改写前
select {
case v, ok = <-c:
... foo
default:
... bar
}
// 改写后
if selected, ok = selectnbrecv(&v, c); selected {
... foo
} else {
... bar
}
|
runtime.selectnbrecv 向 runtime.chanrecv 函数传入的block参数为false,因此当不存在等待的发送者且缓冲区中也没有数据时,当前 Goroutine 不会被阻塞而是直接返回。详见:接收数据。
1
2
3
| func selectnbrecv(elem unsafe.Pointer, c *hchan) (selected, received bool) {
return chanrecv(c, elem, false)
}
|
在默认情况下,编译器会使用如下流程处理select语句:
上述过程可以用示例代码表示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| sel := make([]scase, len(cases))
nsends, nrecvs := 0, 0
dflt := -1
for i, rc := range cases {
var j int
switch rc.dir {
case selectDefault:
dflt = i
continue
case selectSend:
j = nsends
nsends++
case selectRecv:
nrecvs++
j = len(cases) - nrecvs
}
sel[j] = scase{c: rc.ch, elem: rc.val}
}
order := make([]uint16, 2*(nsends+nrecvs))
var pc0 *uintptr
chosen, recvOK := selectgo(&sel[0], &order[0], pc0, nsends, nrecvs, dflt == -1)
if chosen == 0 {
...
break
}
if chosen == 1 {
...
break
}
...
if chosen == len(cases) {
...
break
}
|
Go 语言的defer会在当前函数返回前执行传入的函数,经常用于关闭文件描述符、关闭数据库连接以及解锁资源。
runtime._defer 结构体是延迟调用链表中的一个元素,所有的结构体都会通过link字段串联成链表:
1
2
3
4
5
6
7
8
9
10
11
12
| type _defer struct {
heap bool
rangefunc bool // true for rangefunc list
sp uintptr // sp at time of defer
pc uintptr // pc at time of defer
fn func() // can be nil for open-coded defers
link *_defer // next defer on G; can point to either heap or stack!
// If rangefunc is true, *head is the head of the atomic linked list
// during a range-over-func execution.
head *atomic.Pointer[_defer]
}
|
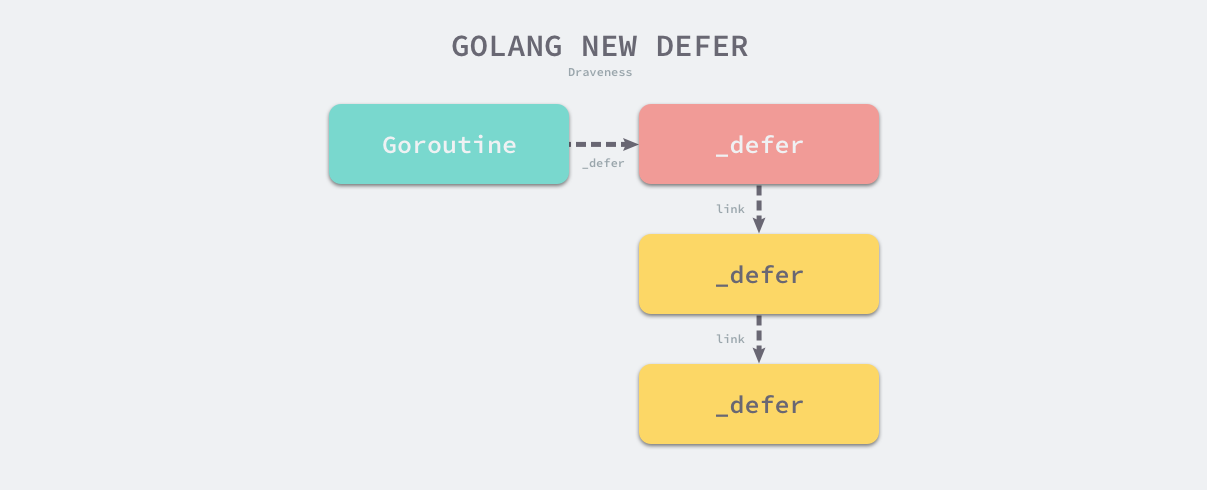
fn字段表示defer关键字传入的函数,曾经是*funcval类型,其指向的函数可以拥有任意签名。而在 runtime: use func() for deferred functions 提交之后,该字段就变成了没有参数和返回值的func()类型。这是因为 Go 语言会在类型检查阶段调用 cmd/compile/internal/typecheck.normalizeGoDeferCall 将OGO和ODEFER声明中形如f(x, y)的函数标准化为:
1
2
| x1, y1 := x, y // added to init
func() { f(x1, y1) }() // result
|
中间代码生成阶段的 cmd/compile/internal/ssagen.stmt 负责处理程序中的defer关键字,该函数会根据情况使用三种不同的执行机制:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| // stmt converts the statement n to SSA and adds it to s.
func (s *state) stmt(n ir.Node) {
...
switch n.Op() {
...
case ir.ODEFER:
n := n.(*ir.GoDeferStmt)
...
if s.hasOpenDefers {
s.openDeferRecord(n.Call.(*ir.CallExpr)) // 开放编码
} else {
d := callDefer // 堆中分配
if n.Esc() == ir.EscNever && n.DeferAt == nil {
d = callDeferStack // 栈上分配
}
s.call(n.Call.(*ir.CallExpr), d, false, n.DeferAt)
}
}
}
|
1
2
3
4
5
| func main() {
for i := 0; i < unpredictableNumber; i++ {
defer fmt.Println(i) // Heap-allocated defer
}
}
|
编译器无法预测示例代码中循环的迭代次数,runtime._defer 的数量会在运行期间改变,因此该结构体只能在堆中分配。在编译器看来,defer也是函数调用,因此会执行 cmd/compile/internal/ssagen.call 为其生成中间代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
| func (s *state) call(n *ir.CallExpr, k callKind, returnResultAddr bool, deferExtra ir.Expr) *ssa.Value {
...
var call *ssa.Value
...
switch {
case k == callDefer:
// 运行期间将调用 runtime.deferproc
sym := ir.Syms.Deferproc
aux := ssa.StaticAuxCall(sym, s.f.ABIDefault.ABIAnalyzeTypes(ACArgs, ACResults))
call = s.newValue0A(ssa.OpStaticLECall, aux.LateExpansionResultType(), aux)
...
}
}
|
Go 语言的编译器不仅将defer转换成了 runtime.deferproc,还通过以下三个步骤为所有调用defer的函数末尾插入 runtime.deferreturn:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| // cmd/compile/internal/walk.walkStmt
func walkStmt(n ir.Node) ir.Node {
...
switch n.Op() {
case ir.ODEFER:
n := n.(*ir.GoDeferStmt)
// 设置当前函数的 hasdefer 属性
ir.CurFunc.SetHasDefer(true)
...
fallthrough
...
}
}
// cmd/compile/internal/ssagen.buildssa
func buildssa(fn *ir.Func, worker int) *ssa.Func {
...
var s state
// 更新 state 的 hasdefer 字段
s.hasdefer = fn.HasDefer()
...
}
// cmd/compile/internal/ssagen.exit
func (s *state) exit() *ssa.Block {
if s.hasdefer {
...
// 在函数返回前插入 runtime.deferreturn
s.rtcall(ir.Syms.Deferreturn, true, nil)
}
...
}
|
上述两个函数是defer运行时机制的入口,分别承担了不同的工作:
1
2
3
4
5
6
7
8
9
10
11
12
| func deferproc(fn func()) {
gp := getg()
d := newdefer()
// 将 _defer 追加到链表最前面
d.link = gp._defer
gp._defer = d
d.fn = fn
d.pc = getcallerpc()
d.sp = getcallersp()
return0()
}
|
runtime.newdefer 的作用是想尽办法获得 runtime._defer 结构体,包含三种方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| func newdefer() *_defer {
var d *_defer
mp := acquirem()
pp := mp.p.ptr()
if len(pp.deferpool) == 0 && sched.deferpool != nil {
lock(&sched.deferlock)
for len(pp.deferpool) < cap(pp.deferpool)/2 && sched.deferpool != nil {
// 从调度器的延迟调用缓存池 sched.deferpool 中取出 _defer
d := sched.deferpool
sched.deferpool = d.link
d.link = nil
// 并追加到当前 Goroutine 的缓存池中
pp.deferpool = append(pp.deferpool, d)
}
unlock(&sched.deferlock)
}
if n := len(pp.deferpool); n > 0 {
// 从 Goroutine 的延迟调用缓存池 pp.deferpool 中取出 _defer
d = pp.deferpool[n-1]
pp.deferpool[n-1] = nil
pp.deferpool = pp.deferpool[:n-1]
}
releasem(mp)
mp, pp = nil, nil
if d == nil {
// 在堆上创建一个新的 _defer
d = new(_defer)
}
d.heap = true
return d
}
|
无论使用哪种方式,runtime._defer 结构体都会被追加到所在 Goroutine _defer链表的最前面。defer关键字的插入顺序是从后向前的,而执行则是从前向后的,这也解释了为什么后调用的defer会先执行:
1
2
3
4
5
6
7
8
9
10
| func main() {
for i := 0; i < 3; i++ {
defer fmt.Println(i)
}
}
$ go run main.go
2
1
0
|
另外,runtime.deferproc 在创建延迟调用时会立刻复制函数的参数,因此后者不会等到真正执行时计算:
1
2
3
4
5
6
7
8
9
10
11
12
| func main() {
n := 1
if n == 1 {
defer fmt.Println(n)
n += 100
}
fmt.Println(n)
}
$ go run main.go
101
1
|
runtime.deferreturn 会在函数返回之前执行 Goroutine _defer链表中注册的所有函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| func deferreturn() {
var p _panic
p.deferreturn = true
p.start(getcallerpc(), unsafe.Pointer(getcallersp()))
for {
// 获取下一个要执行的 defer 函数
fn, ok := p.nextDefer()
// 若没有更多的 defer 函数要执行,则退出循环
if !ok {
break
}
// 执行 defer 函数
fn()
}
}
|
当defer在函数体中最多执行一次时,runtime._defer 会在编译期间被分配到栈上:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| // cmd/compile/internal/ssagen.call
func (s *state) call(n *ir.CallExpr, k callKind, returnResultAddr bool, deferExtra ir.Expr) *ssa.Value {
...
var call *ssa.Value
if k == callDeferStack {
// 在栈上初始化 defer 结构体
t := deferstruct()
// 运行期间将调用 runtime.deferprocStack
ACArgs = append(ACArgs, types.Types[types.TUINTPTR])
aux := ssa.StaticAuxCall(ir.Syms.DeferprocStack, s.f.ABIDefault.ABIAnalyzeTypes(ACArgs, ACResults))
callArgs = append(callArgs, addr, s.mem())
call = s.newValue0A(ssa.OpStaticLECall, aux.LateExpansionResultType(), aux)
call.AddArgs(callArgs...)
call.AuxInt = int64(types.PtrSize)
}
...
}
|
runtime.deferprocStack 只需要设置一些未在编译期间初始化的字段,就可以把defer结构体追加到 Goroutine 的延迟调用链表中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| func deferprocStack(d *_defer) {
gp := getg()
d.heap = false
d.rangefunc = false
d.sp = getcallersp()
d.pc = getcallerpc()
// The lines below implement:
// d.panic = nil
// d.fd = nil
// d.link = gp._defer
// d.head = nil
// gp._defer = d
*(*uintptr)(unsafe.Pointer(&d.link)) = uintptr(unsafe.Pointer(gp._defer))
*(*uintptr)(unsafe.Pointer(&d.head)) = 0
*(*uintptr)(unsafe.Pointer(&gp._defer)) = uintptr(unsafe.Pointer(d))
return0()
}
|
除了分配位置不同,栈上分配和堆中分配并没有本质区别,前者可以适用于绝大多数场景。
开放编码将defer调用直接内联到函数末尾以及汇编代码中每一个返回语句之前,仅在满足以下条件时启用:
- 函数的
defer数量少于或者等于 8 个; - 函数的
defer关键字不能在循环中执行; - 函数的
return语句与defer语句的乘积小于或者等于 15 个。
否则,最终生成的二进制代码将会非常臃肿。除上述几个条件外,也有其他条件会限制开放编码的使用。不过它们都是不太重要的细节,这里不会深究。
Go 语言会在编译期间决定是否启用开放编码。在编译器生成中间代码之前,cmd/compile/internal/walk.walkStmt 会 修改已经生成的抽象语法树,设置函数体上的OpenCodedDeferDisallowed属性:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| func walkStmt(n ir.Node) ir.Node {
...
case ir.ODEFER:
...
// 函数的 defer 数量大于 8
if ir.CurFunc.NumDefers > maxOpenDefers || n.DeferAt != nil {
ir.CurFunc.SetOpenCodedDeferDisallowed(true)
}
// defer 在循环中出现
if n.Esc() != ir.EscNever {
ir.CurFunc.SetOpenCodedDeferDisallowed(true)
}
fallthrough
...
}
|
我们在 SSA 中间代码生成阶段的 cmd/compile/internal/ssagen.buildssa 函数中也能够看到启用开放编码优化的其他条件:
1
2
3
4
5
6
7
8
9
10
11
| func buildssa(fn *ir.Func, worker int) *ssa.Func {
...
s.hasOpenDefers = base.Flag.N == 0 && s.hasdefer && !s.curfn.OpenCodedDeferDisallowed()
...
if s.hasOpenDefers &&
// return 和 defer 语句数量的乘积大于 15
s.curfn.NumReturns*s.curfn.NumDefers > 15 {
s.hasOpenDefers = false
}
...
}
|
延迟比特和延迟记录是使用开放编码实现defer的两个最重要结构,Go 语言会在编译期间调用 cmd/compile/internal/ssagen.buildssa 在栈上初始化大小为 8 个比特的deferBits变量。
该变量中的每个比特位都表示对应的defer关键字是否需要被执行。如下图所示,倒数第二个比特位被设置成了 1,那么其对应的函数将在函数返回前执行:

编译器还会通过 cmd/compile/internal/ssagen.openDeferRecord 添加代码以评估和存储defer调用的函数,并记录有关defer的信息。传入defer的函数和参数存储在 cmd/compile/internal/ssagen.openDeferInfo 结构体中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| func (s *state) openDeferRecord(n *ir.CallExpr) {
...
opendefer := &openDeferInfo{
n: n,
}
fn := n.Fun
closureVal := s.expr(fn)
closure := s.openDeferSave(fn.Type(), closureVal)
opendefer.closureNode = closure.Aux.(*ir.Name)
if !(fn.Op() == ir.ONAME && fn.(*ir.Name).Class == ir.PFUNC) {
opendefer.closure = closure
}
index := len(s.openDefers)
s.openDefers = append(s.openDefers, opendefer)
bitvalue := s.constInt8(types.Types[types.TUINT8], 1<<uint(index))
newDeferBits := s.newValue2(ssa.OpOr8, types.Types[types.TUINT8], s.variable(deferBitsVar, types.Types[types.TUINT8]), bitvalue)
s.vars[deferBitsVar] = newDeferBits
s.store(types.Types[types.TUINT8], s.deferBitsAddr, newDeferBits)
}
|
在函数返回前,cmd/compile/internal/ssagen.openDeferExit 将处理所有使用开放编码优化的defer关键字,检查延迟比特的每个位以确定是否执行了相应的defer语句:
1
2
3
4
5
6
7
8
9
10
| // cmd/compile/internal/ssagen.exit
func (s *state) exit() *ssa.Block {
if s.hasdefer {
if s.hasOpenDefers {
...
s.openDeferExit()
}
}
...
}
|
上述优化过程可以用伪码表示为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| deferBits := 0 // 初始化延迟比特
deferBits |= 1<<0 // 延迟比特最后一位设为 1
_f1, _a1 := f1, a1 // 保存函数及参数
if condition {
deferBits |= 1<<1 // 若条件满足,延迟比特倒数第二位设为 1
_f2, _a2 := f2, a2 // 保存函数及参数
}
exit:
if deferBits & 1<<1 != 0 { // 00000011 & 00000010 != 0
deferBits &^= 1<<1 // 将倒数第二位复原为 0 以进行下一次判断
_f2(_a2)
}
if deferBits & 1<<0 != 0 { // 00000001 & 00000001 != 0
deferBits &^= 1<<0
_f1(_a1)
}
|
综上所述,开放编码使用延迟比特和 cmd/compile/internal/ssagen.openDeferInfo 结构体存储defer的相关信息,将其直接在当前函数内展开,并在返回前根据延迟比特位决定是否执行调用。这种方法只使用了少量的位运算指令和内存资源,因此性能最好。
panic能够改变程序的控制流。调用panic后会立刻停止执行当前函数的剩余代码,并递归执行当前 Goroutine 中的defer;recover可以中止panic造成的程序崩溃,不过只能在defer中发挥作用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| func badCall() {
panic("bad end")
}
func test() {
defer func() {
if e := recover(); e != nil {
fmt.Printf("Panicing %s\r\n", e)
}
}()
badCall()
fmt.Printf("After bad call\r\n") // 无法到达
}
func main() {
fmt.Printf("Calling test\r\n")
test()
fmt.Printf("Test completed\r\n")
}
$ go run main.go
Calling test
Panicing bad end
Test completed
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| type _panic struct {
argp unsafe.Pointer // 指向发生 panic 时执行 defer 调用的参数的指针
arg any // panic 的参数
link *_panic // 指向更早的 runtime._panic
// 调用 _panic.start 时的程序计数器和栈指针
startPC uintptr
startSP unsafe.Pointer
// 调用 defer 时的栈帧
sp unsafe.Pointer
lr uintptr
fp unsafe.Pointer
// 存储 panic 应当跳转回去的程序计数器位置
retpc uintptr
// 用于处理开放编码优化的 defer
deferBitsPtr *uint8
slotsPtr unsafe.Pointer
recovered bool // 是否已经被 recover 恢复
goexit bool // 保证 rutime.Goexit 不会被 defer 中的
// panic 和 recover 取消
deferreturn bool
}
|
runtime._panic 中的link字段与 runtime._defer 类似,因此panic关键字也支持嵌套调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| func main() {
defer fmt.Println("in main")
defer func() {
defer func() {
panic("panic again and again")
}()
panic("panic again")
}()
panic("panic once")
}
$ go run main.go
in main
panic: panic once
panic: panic again
panic: panic again and again
goroutine 1 [running]:
...
exit status 2
|
编译器会将关键字panic转换成 runtime.gopanic:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| func gopanic(e any) {
...
// 初始化 runtime._panic
var p _panic
p.arg = e
runningPanicDefers.Add(1)
// *_panic.start 设置 _panic 结构体的字段
// 并将其添加到所在 Goroutine _panic 链表的最前端
p.start(getcallerpc(), unsafe.Pointer(getcallersp()))
// 不断从当前 Goroutine _defer 链表中获取并执行 defer 调用
for {
fn, ok := p.nextDefer()
if !ok {
break
}
fn()
}
preprintpanics(&p)
// 终止整个程序
fatalpanic(&p)
*(*int)(nil) = 0
}
|
该函数最后调用的 runtime.fatalpanic 实现了无法被恢复的程序崩溃:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| func fatalpanic(msgs *_panic) {
pc := getcallerpc()
sp := getcallersp()
gp := getg()
var docrash bool
systemstack(func() {
if startpanic_m() && msgs != nil {
runningPanicDefers.Add(-1)
// 打印全部 panic 消息以及调用时传入的参数
printpanics(msgs)
}
docrash = dopanic_m(gp, pc, sp)
})
if docrash {
crash()
}
// 退出当前程序并返回错误码 2
systemstack(func() {
exit(2)
})
*(*int)(nil) = 0
}
|
编译器会将关键字recover转换为 runtime.gorecover:
1
2
3
4
5
6
7
8
9
10
11
| func gorecover(argp uintptr) any {
gp := getg()
p := gp._panic
if p != nil && !p.goexit && !p.recovered && argp == uintptr(p.argp) {
// 修改 runtime._panic 的 recovered 字段
p.recovered = true
// 返回 panic 的参数
return p.arg
}
return nil
}
|
p != nil:如果当前 Goroutine 没有panic,该函数将返回nil。因此,recover只能在defer调用中生效:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| func main() {
defer fmt.Println("in main")
if err := recover(); err != nil {
fmt.Println(err)
}
panic("unknown err")
}
$ go run main.go
in main
panic: unknown err
goroutine 1 [running]:
...
exit status 2
|
argp == uintptr(p.argp):runtime.gorecover 的参数argp是当前栈帧的栈指针,而p.argp则是发生panic时执行defer调用的参数的指针。因此,下面两段代码,第一段的panic可以recover,第二段则不会:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| // 第一段
func main() {
defer func() {
// argp 为 匿名函数的栈指针
recover()
}()
panic("ooo")
}
// 第二段
func main() {
// argp 为 main 函数的栈指针
defer recover()
panic("ooo")
}
|
runtime.gorecover 中并不包含恢复程序的逻辑,这项工作是由 runtime.recovery 完成的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| func gopanic(e any) {
...
for {
fn, ok := p.nextDefer()
if !ok {
break
}
fn()
}
...
}
func (p *_panic) nextDefer() (func(), bool) {
gp := getg()
if !p.deferreturn {
if gp._panic != p {
throw("bad panic stack")
}
if p.recovered {
mcall(recovery) // 不会返回
throw("recovery failed")
}
}
...
}
func recovery(gp *g) {
p := gp._panic
pc, sp, fp := p.retpc, uintptr(p.sp), uintptr(p.fp)
p0, saveOpenDeferState := p, p.deferBitsPtr != nil && *p.deferBitsPtr != 0
...
gp.sched.sp = sp
gp.sched.pc = pc
gp.sched.lr = 0
...
// 将函数的返回值设置为 1
gp.sched.ret = 1
// 根据 pc 和 sp 跳回 defer 关键字调用的位置
gogo(&gp.sched)
}
|
runtime.deferproc的 注释 表明,当函数的返回值为 1 时,编译器生成的代码会直接跳转到 runtime.deferreturn 并恢复到正常的执行流程。
make:初始化内置的数据结构,如切片、哈希表和管道;new:根据传入的类型分配一片内存空间并返回指向这片内存空间的指针;
在类型检查阶段,编译器会将代表make关键字的OMAKE节点根据参数类型转换成OMAKESLICE、OMAKEMAP和OMAKECHAN三种不同的节点。这些节点调用不同的运行时函数初始化对应的数据结构。
编译器在中间代码生成的 遍历和替换 阶段调用 cmd/compile/internal/walk.walkExpr1 和 cmd/compile/internal/walk.walkNew 决定变量的分配方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
...
case ir.ONEW:
n := n.(*ir.UnaryExpr)
return walkNew(n, init)
...
}
}
func walkNew(n *ir.UnaryExpr, init *ir.Nodes) ir.Node {
t := n.Type().Elem()
// 该类型无法分配到堆上
if t.NotInHeap() {
base.Errorf("%v can't be allocated in Go; it is incomplete (or unallocatable)", n.Type().Elem())
}
// 变量没有逃逸到堆上
if n.Esc() == ir.EscNone {
// 类型的大小超过了编译器允许的隐式栈变量的最大大小
if t.Size() > ir.MaxImplicitStackVarSize {
base.Fatalf("large ONEW with EscNone: %v", n)
}
// 在栈上分配变量 tmp 并将 &tmp 表达式附加到 init
return stackTempAddr(init, t)
}
// 计算类型的大小和对齐方式
types.CalcSize(t)
n.MarkNonNil()
return n
}
|
如果变量需要被分配到堆上,new关键字后续将由 cmd/compile/internal/ssagen.*state.expr 等函数处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| func (s *state) expr(n ir.Node) *ssa.Value {
return s.exprCheckPtr(n, true)
}
func (s *state) exprCheckPtr(n ir.Node, checkPtrOK bool) *ssa.Value {
...
switch n.Op() {
...
case ir.ONEW:
n := n.(*ir.UnaryExpr)
var rtype *ssa.Value
if x, ok := n.X.(*ir.DynamicType); ok && x.Op() == ir.ODYNAMICTYPE {
rtype = s.expr(x.RType)
}
return s.newObject(n.Type().Elem(), rtype)
...
}
}
func (s *state) newObject(typ *types.Type, rtype *ssa.Value) *ssa.Value {
// 若申请的空间为 0,则返回一个表示空指针的 Zerobase
if typ.Size() == 0 {
return s.newValue1A(ssa.OpAddr, types.NewPtr(typ), ir.Syms.Zerobase, s.sb)
}
if rtype == nil {
rtype = s.reflectType(typ)
}
// 将关键字转换为 runtime.Newobject
return s.rtcall(ir.Syms.Newobject, true, []*types.Type{types.NewPtr(typ)}, rtype)[0]
}
|
runtime.newobject 根据传入类型所占空间的大小,调用 runtime.mallocgc 在堆中申请一块内存并返回指向它的指针:
1
2
3
| func newobject(typ *_type) unsafe.Pointer {
return mallocgc(typ.Size_, typ, true)
}
|
使用var关键字初始化变量的过程与之类似:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| // cmd/compile/internal/ssagen.*state.stmt
func (s *state) stmt(n ir.Node) {
...
switch n.Op() {
...
case ir.ODCL:
n := n.(*ir.Decl)
// 若变量逃逸到堆上
if v := n.X; v.Esc() == ir.EscHeap {
s.newHeapaddr(v)
}
...
}
}
// cmd/compile/internal/ssagen.*state.newHeapaddr
func (s *state) newHeapaddr(n *ir.Name) {
s.setHeapaddr(n.Pos(), n, s.newObject(n.Type(), nil))
}
|