前言
在 Kubernetes Pod 是如何跨节点通信的? 中,我们简单地介绍了 Kubernetes 中的两种 SDN 网络模型:Underlay 和 Overlay。而 Openshift 中的 SDN 则是由 Overlay 网络 OVS(Open vSwitch)实现的,其使用的插件如下:
- ovs-subnet: 默认插件,提供一个扁平化的 Pod 网络以实现 Pod 与其他任何 Pod 或 Service 的通信;
- ovs-multitenant:实现多租户管理,隔离不同 Project 之间的网络通信。每个 Project 都有一个 NETID(即 VxLAN 中的 VNID),可以使用
oc get netnamespaces命令查看; - ovs-networkpolicy:基于 Kubernetes 中的 NetworkPolicy 资源实现网络策略管理。
OVS 在每个 Openshift 节点上都创建了如下网络接口:
br0:OpenShift 创建和管理的 OVS 网桥,它会使用 OpenFlow 流表来实现数据包的转发和隔离;vxlan0:VxLAN 隧道端点,即 VTEP(Virtual Tunnel End Point)。用于集群内部的 Pod 跨节点通信;tun0:节点上所有 Pod 的默认网关,用于 Pod 与集群外部以及 Pod 与 Service 之间的通信;veth:Pod 通过veth-pair连接到br0网桥的端点。
使用以下命令可以查看br0上的所有端口及其编号:
| |
考虑到 Openshift 集群的复杂性,我们分别按以下几种场景分析数据包的流向:
- 节点内 Pod 互访:Pod to Local Pod
- Pod 跨节点互访:Pod to Remote Pod
- Pod 访问 Service:Pod to Service
- Pod 与集群外部互访:Pod to External
由于 3.11 以上版本的 Openshift 不再以守护进程而是以 Pod 的形式部署 OVS 组件,不方便对 OpenFlow 流表进行查看,本文选用的集群版本为 3.6:
| |
另外,实验用集群并未开启 ovs-multitenant,即未进行多租户隔离。整个集群 Pod 网络是扁平化的,所有 Pod 的 VNID 都为默认值 0。
Pod to Local Pod
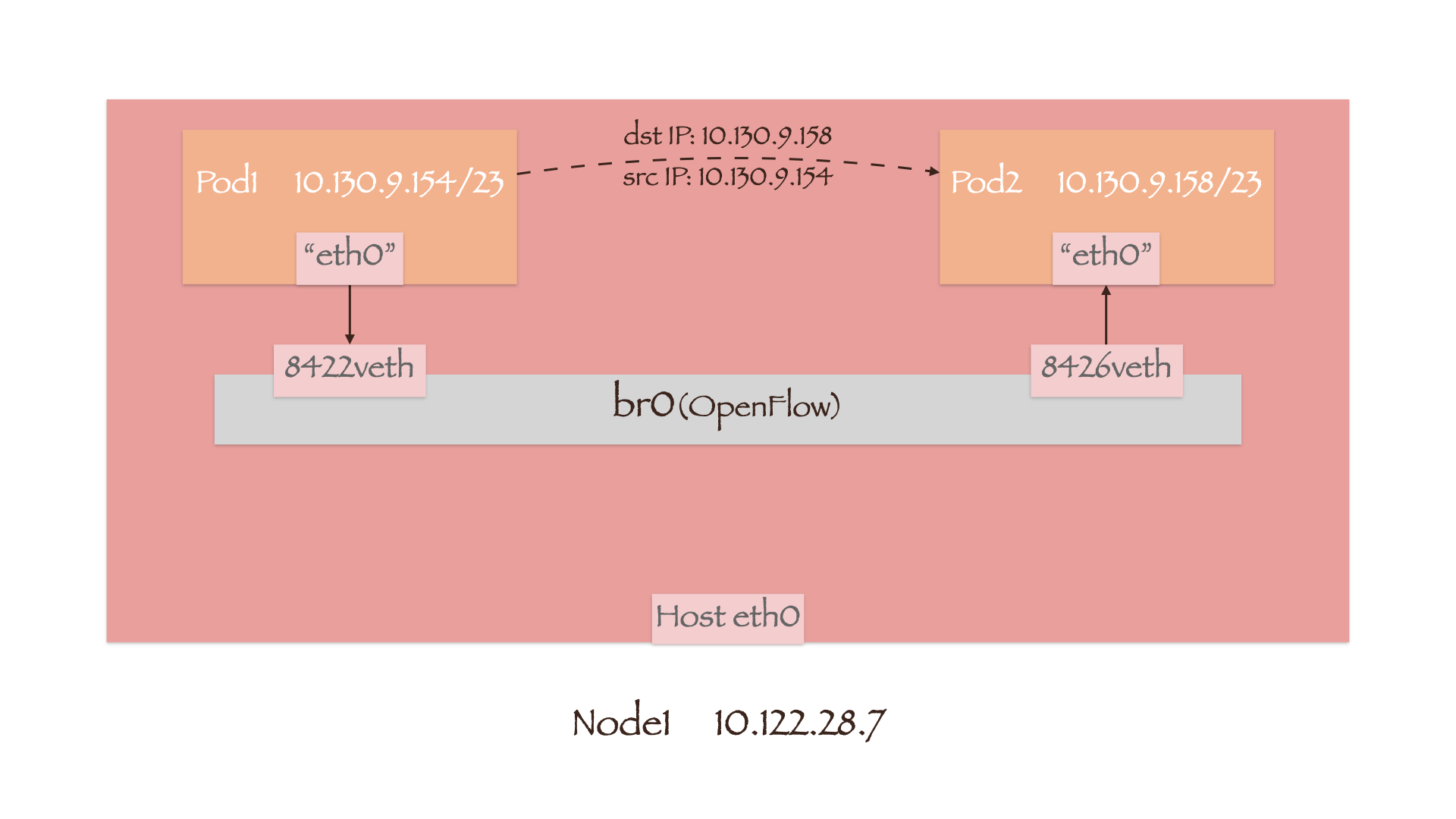
数据包首先通过veth-pair送往 OVS 网桥br0,随后便进入了br0上的 OpenFlow 流表。我们可以用ovs-ofctl -O OpenFlow13 dump-flows br0命令查看流表中的规则,同时为了让输出结果更加简洁,略去 cookie 和 duration 的信息:
table=0, n_packets=62751550874, n_bytes=25344802160312, priority=200,ip,in_port=1,nw_src=10.128.0.0/14,nw_dst=10.130.8.0/23 actions=move:NXM_NX_TUN_ID[0..31]->NXM_NX_REG0[],goto_table:10table=0, n_packets=1081527047094, n_bytes=296066911370148, priority=200,ip,in_port=2 actions=goto_table:30table=0, n_packets=833353346930, n_bytes=329854403266173, priority=100,ip actions=goto_table:20
table0 中关于 IP 数据包的规则主要有三条,其中前两条分别对应流入端口in_port为 1 号端口vxlan0和 2 号端口tun0的数据包。这两条规则的优先级priority都是 200,因此只有在两者均不符合情况下,才会匹配第三条规则。本地 Pod 发出的数据包是由veth端口进入的,因此将转到 table20;
table=20, n_packets=607178746, n_bytes=218036511085, priority=100,ip,in_port=8422,nw_src=10.130.9.154 actions=load:0->NXM_NX_REG0[],goto_table:21table=21, n_packets=833757781068, n_bytes=329871389393381, priority=0 actions=goto_table:30
table20 会匹配源地址nw_src为 10.130.9.154 且流入端口in_port为 8422 的数据包,随后将 Pod1 的 VNID 0 作为源 VNID 存入寄存器 0 中,经由 table21 转到 table30;
table=30, n_packets=1116329752668, n_bytes=294324730186808, priority=200,ip,nw_dst=10.130.8.0/23 actions=goto_table:70table=30, n_packets=59672345347, n_bytes=41990349575805, priority=100,ip,nw_dst=10.128.0.0/14 actions=goto_table:90table=30, n_packets=21061319859, n_bytes=29568807363654, priority=100,ip,nw_dst=172.30.0.0/16 actions=goto_table:60table=30, n_packets=759636044089, n_bytes=280576476818108, priority=0,ip actions=goto_table:100
table30 中匹配数据包目的地址nw_dst的规则有四条,前三条分别对应本节点内 Pod 的 CIDR 网段 10.130.8.0/23、集群内 Pod 的 CIDR 网段 10.128.0.0/14 和 Service 的 ClusterIP 网段 172.30.0.0/16。第四条优先级最低,用于 Pod 对集群外部的访问。数据包的目的地址 10.130.9.158 符合第一条规则,且第一条规则的优先级最高,因此将转到 table70;
table=70, n_packets=597219981, n_bytes=243824445346, priority=100,ip,nw_dst=10.130.9.158 actions=load:0->NXM_NX_REG1[],load:0x20ea->NXM_NX_REG2[],goto_table:80
table70 匹配目的地址nw_dst为 Pod2 IP 10.130.9.158 的数据包,并将 Pod2 的 VNID 0 作为目的 VNID 存入寄存器 1 中。同时端口号0x20ea被保存到寄存器 2 中,然后转到 table80;
table=80, n_packets=1112713040332, n_bytes=293801616636499, priority=200 actions=output:NXM_NX_REG2[]
table80 比较寄存器 0 和寄存器 1 中保存的源/目的 VNID。若二者一致,则根据寄存器 2 中保存的端口号将数据包送出。
端口号0x20ea是一个十六进制数字,即十进制数 8426。而 Pod2 正是通过 8426 号端口设备vethba48c6de连接到br0上,因此数据包便最终通过它流入到了 Pod2 中。
| |
Pod to Remote Pod
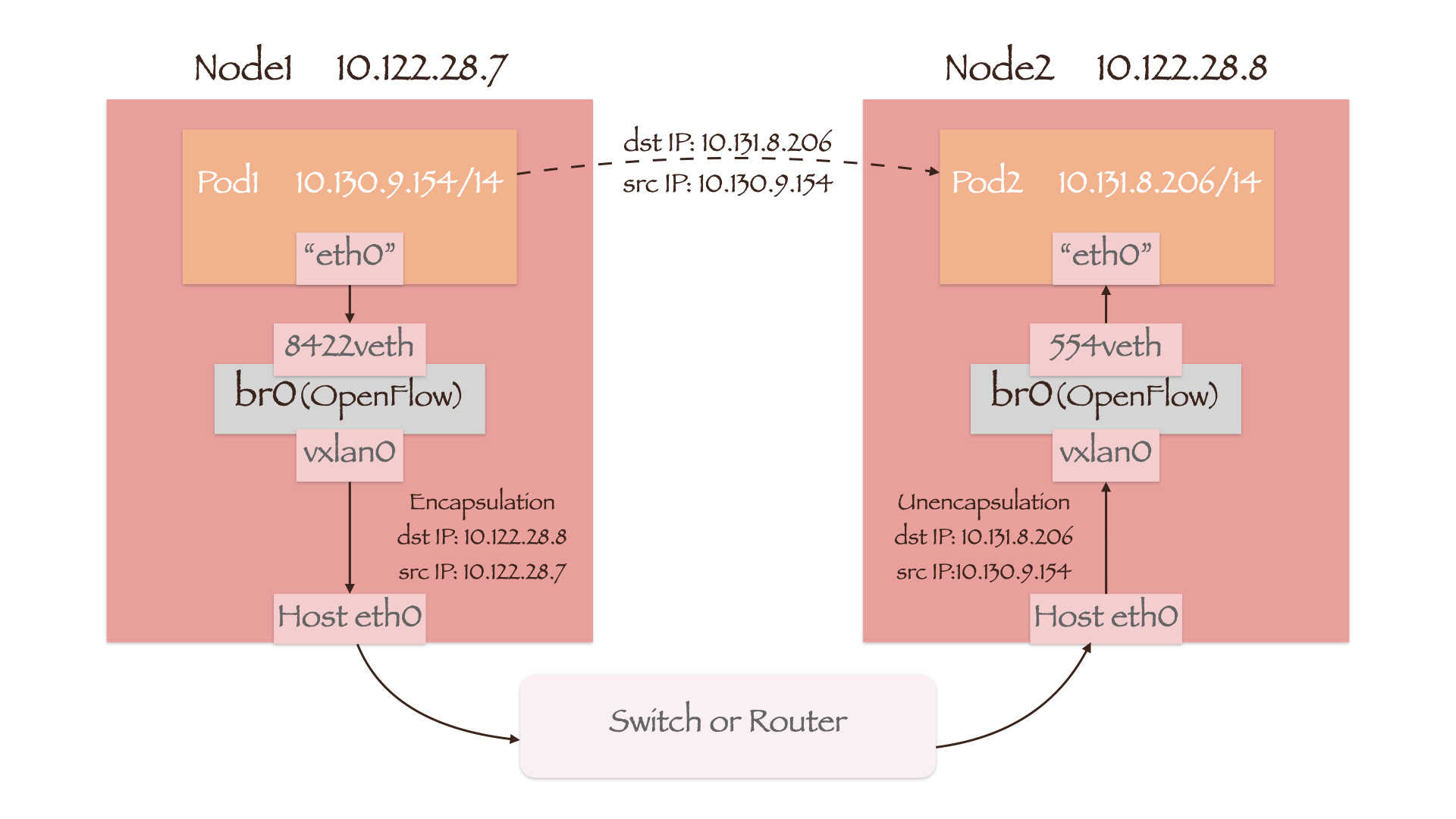
Packet in Local Pod
数据包依然首先通过veth-pair送往 OVS 网桥br0,随后便进入了br0上的 OpenFlow 流表:
table=0, n_packets=830232155588, n_bytes=328613498734351, priority=100,ip actions=goto_table:20table=20, n_packets=1901, n_bytes=299279, priority=100,ip,in_port=6635,nw_src=10.130.9.154 actions=load:0->NXM_NX_REG0[],goto_table:21table=21, n_packets=834180030914, n_bytes=330064497351030, priority=0 actions=goto_table:30
与 Pod to Local Pod 的流程一致,数据包根据规则转到 table30;
table=30, n_packets=59672345347, n_bytes=41990349575805, priority=100,ip,nw_dst=10.128.0.0/14 actions=goto_table:90table=30, n_packets=1116329752668, n_bytes=294324730186808, priority=200,ip,nw_dst=10.130.8.0/23 actions=goto_table:70
数据包的目的地址为 Pod2 IP 10.131.8.206,不属于本节点 Pod 的 CIDR 网段 10.130.8.0/23,而属于集群 Pod 的 CIDR 网段 10.128.0.0/14,因此转到 table90;
table=90, n_packets=15802525677, n_bytes=6091612778189, priority=100,ip,nw_dst=10.131.8.0/23 actions=move:NXM_NX_REG0[]->NXM_NX_TUN_ID[0..31],set_field:10.122.28.8->tun_dst,output:1
table90 根据目的 IP 的所属网段 10.131.8.0/23 判断其位于 Node2 上,于是将 Node2 IP 10.122.28.8 设置为tun_dst。并且从寄存器 0 中取出 VNID 的值,从 1 号端口vxlan0输出。
vxlan0作为一个 VTEP 设备(参见 Overlay Network),将根据 table90 发来的信息,对数据包进行一层封装:
- 目的地址(dst IP) –>
tun_dst–> 10.122.28.8 - 源地址(src IP) –> Node1 IP –> 10.122.28.7
- 源 VNID –>
NXM_NX_TUN_ID[0..31]–> 0
封装后的数据包源/目的地址均为节点 IP,因此从 Node1 的网卡流出后,可以通过物理网络设备转发到 Node2 上。
Packet in Remote Pod
Node2 上的vxlan0对数据包进行解封,随后从br0上的 1 号端口进入 OpenFlow 流表中:
table=0, n_packets=52141153195, n_bytes=17269645342781, priority=200,ip,in_port=1,nw_src=10.128.0.0/14,nw_dst=10.131.8.0/23 actions=move:NXM_NX_TUN_ID[0..31]->NXM_NX_REG0[],goto_table:10
table0 判断数据包的流入端口in_port、源 IP 所属网段nw_src和目的 IP 所属网段nw_dst均符合该条规则,于是保存数据包中的源 VNID 到寄存器 0 后转到 table10;
table=10, n_packets=10147760036, n_bytes=4060517391502, priority=100,tun_src=10.122.28.7 actions=goto_table:30
table10 确认 VxLAN 隧道的源 IPtun_src就是节点 Node1 的 IP 地址,于是转到 table30;
table=30, n_packets=678759566065, n_bytes=172831151192704, priority=200,ip,nw_dst=10.131.8.0/23 actions=goto_table:70
table30 确认数据包的目的 IP(即 Pod2 IP)存在于 Node2 中 Pod 的 CIDR 网段内,因此转到 table70;
table=70, n_packets=193211683, n_bytes=27881218388, priority=100,ip,nw_dst=10.131.8.206 actions=load:0->NXM_NX_REG1[],load:0x220->NXM_NX_REG2[],goto_table:80
table70 发现数据包的目的 IP 与 Pod2 IP 相符,于是将 Pod2 的 VNID 作为目的 VNID 存于寄存器 1 中,将0x220(十进制数 544)保存在寄存器 2 中,然后转到 table80;
table=80, n_packets=676813794014, n_bytes=172576112594488, priority=200 actions=output:NXM_NX_REG2[]
table80 会检查保存在寄存器 0 和寄存器 1 中的源/目的 VNID,若相等(此例中均为 0),则从 544 号端口输出。
br0上的 544 端口对应的网络接口是vethe9f523a9,因此数据包便最终通过它流入到了 Pod2 中。
| |
Pod to Service
在本例中,Pod1 通过 Service 访问其后端的 Pod2,其 ClusterIP 为 172.30.107.57,监听的端口为 8080:
| |
table=30, n_packets=21065939280, n_bytes=29573447694924, priority=100,ip,nw_dst=172.30.0.0/16 actions=goto_table:60
数据包在送到 OpenFlow 流表 table30 前的步骤与 Pod to Local Pod 和 Pod to Remote Pod 中的情况一致,但数据包的目的地址变为了 myService 的 ClusterIP。因此将匹配nw_dst中的 172.30.0.0/16 网段,转到 table60;
table=60, n_packets=0, n_bytes=0, priority=100,tcp,nw_dst=172.30.107.57,tp_dst=8080 actions=load:0->NXM_NX_REG1[],load:0x2->NXM_NX_REG2[],goto_table:80
table60 匹配目的地址nw_dst为 172.30.107.57 且目的端口为 8080 的数据包,并将 Pod1 的 VNID 0 保存到寄存器 1 中,将0x2(十进制数字 2)保存到寄存器 2 中,转到 table80;
table=80, n_packets=1113435014018, n_bytes=294106102133061, priority=200 actions=output:NXM_NX_REG2[]
table80 根据寄存器 2 中的数字将数据包从 2 号端口tun0传出,随后进入节点的 iptables 处理流中:
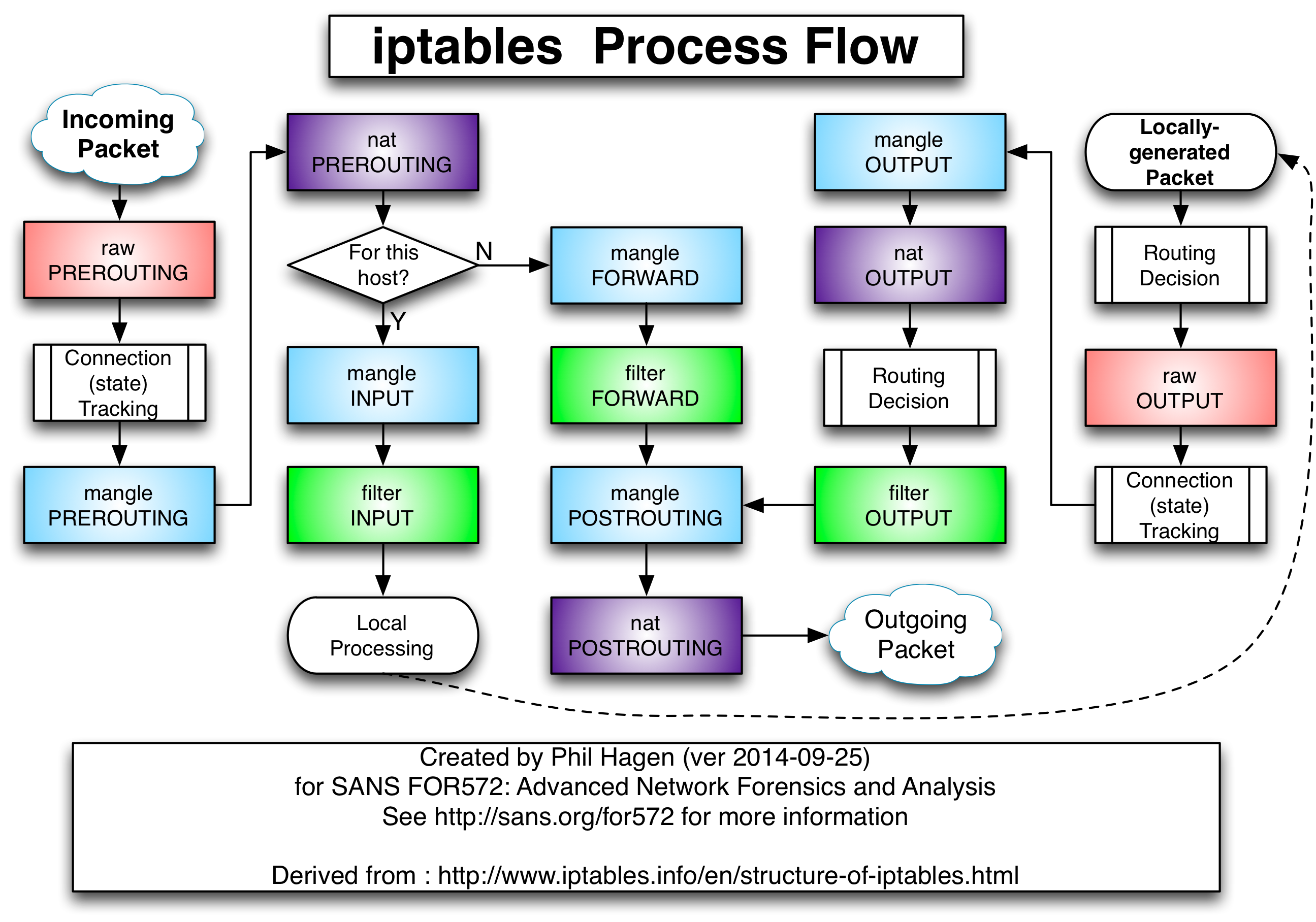
由于 Service 的实现依赖于 NAT(上图中的紫色方框),我们可以在 NAT 表中看到与之相关的规则:
| |
本机产生的数据包(Locally-generated Packet)首先进入OUTPUT链,然后匹配到自定义链KUBE-SERVICES。其目的地址为 Service 的 ClusterIP 172.30.107.57,因此将再次跳转到对应的KUBE-SVC-QYWOVDCBPMWAGC37链:
| |
KUBE-SVC-QYWOVDCBPMWAGC37链下有两条完全相同的匹配规则,对应了该 Service 后端的两个 Pod。KUBE-SEP-ADAJHSV7RYS5DUBX链和 KUBE-SEP-AF5DIL6JV3XLLV6G链能够执行 DNAT 操作,分别将数据包的目的地址转化为 Pod IP 10.131.8.206 和 10.128.10.57。在一次通信中只会有一条链生效,这体现了 Service 的负载均衡能力。
完成OUTPUTDNAT 的数据包将进入节点的路由判断(Routing Decision)。由于当前目的地址已经属于集群内 Pod 的 CIDR 网段 10.128.0.0/14,数据包将从tun0端口再次进入 OVS 网桥br0中。
| |
不过数据包在进入br0之前,还需要经过 iptables 中的POSTROUTING链,完成一次MASQUERADE:数据包的源地址转换为其传出端口的 IP,即tun0的 IP 10.130.8.1。
| |
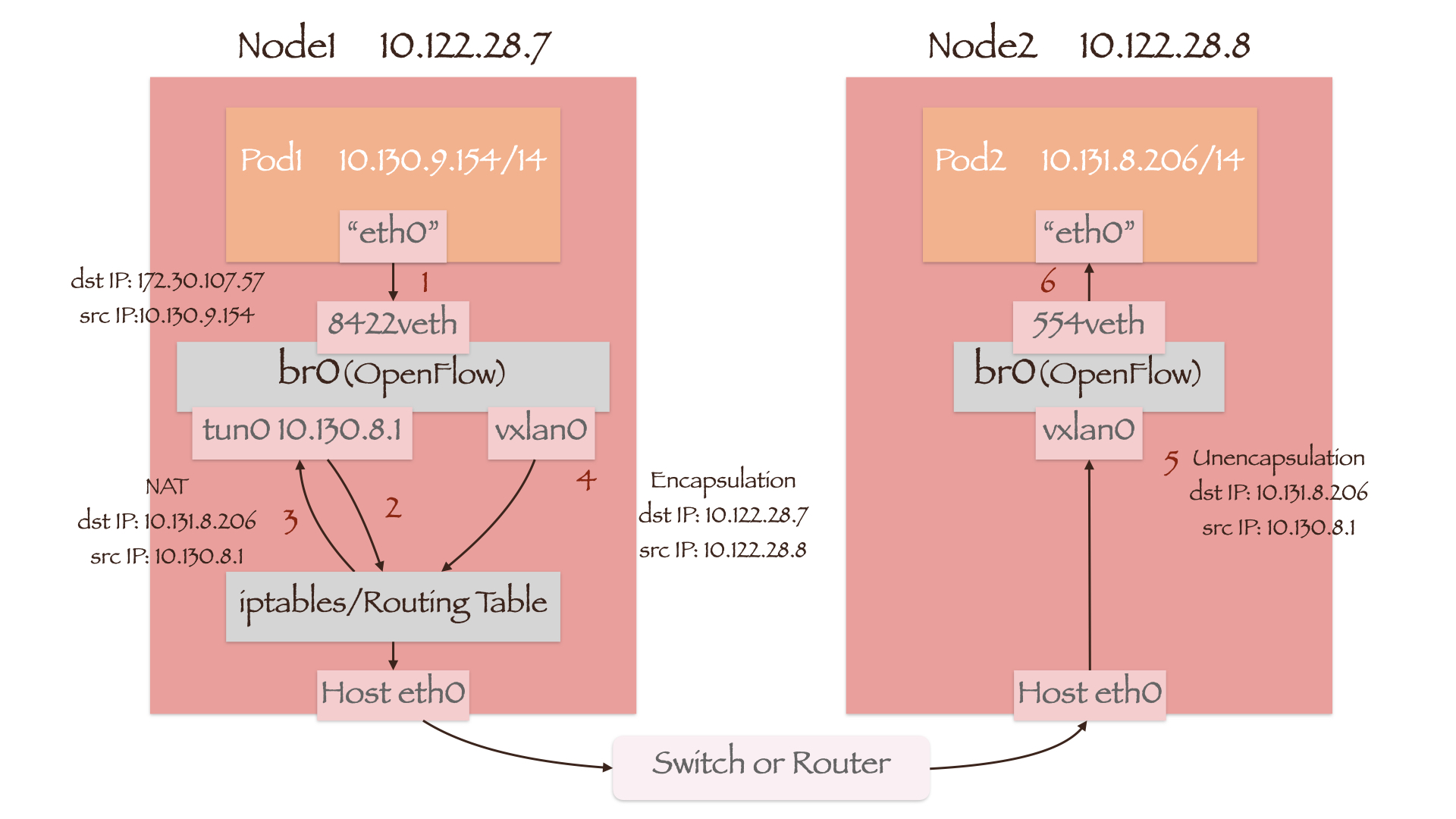
本例中 Service 的后端 Pod 均在 Pod1 所在的节点外,因此数据包第二次进入 OpenFlow 流表时匹配的规则基本与 Pod to Remote Pod 一致:
table=0, n_packets=1081527047094, n_bytes=296066911370148, priority=200,ip,in_port=2 actions=goto_table:30table=30, n_packets=59672345347, n_bytes=41990349575805, priority=100,ip,nw_dst=10.128.0.0/14 actions=goto_table:90table=90, n_packets=15802525677, n_bytes=6091612778189, priority=100,ip,nw_dst=10.131.8.0/23 actions=move:NXM_NX_REG0[]->NXM_NX_TUN_ID[0..31],set_field:10.122.28.8->tun_dst,output:1
其传递流程如下图所示:
Pod2 返回的数据包在到达 Node1 后将被vxlan0解封装,然后根据其目的地址tun0进入 OpenFlow 流表:
table=0, n_packets=1084362760247, n_bytes=297224518823222, priority=200,ip,in_port=2 actions=goto_table:30table=30, n_packets=20784385211, n_bytes=4742514750371, priority=300,ip,nw_dst=10.130.8.1 actions=output:2
数据包从 2 号端口tun0送出后进入节点的 iptables 处理流,随后将触发 Connection Tracking:根据/proc/net/nf_conntrack文件中的记录进行“DeNAT”。返回数据包的源/目的地址从 Pod2 IP 10.131.8.206 和 tun0 IP 10.130.8.1,变回 Service 的 ClusterIP 172.30.107.57 和 Pod1 IP 10.130.9.154。
| |
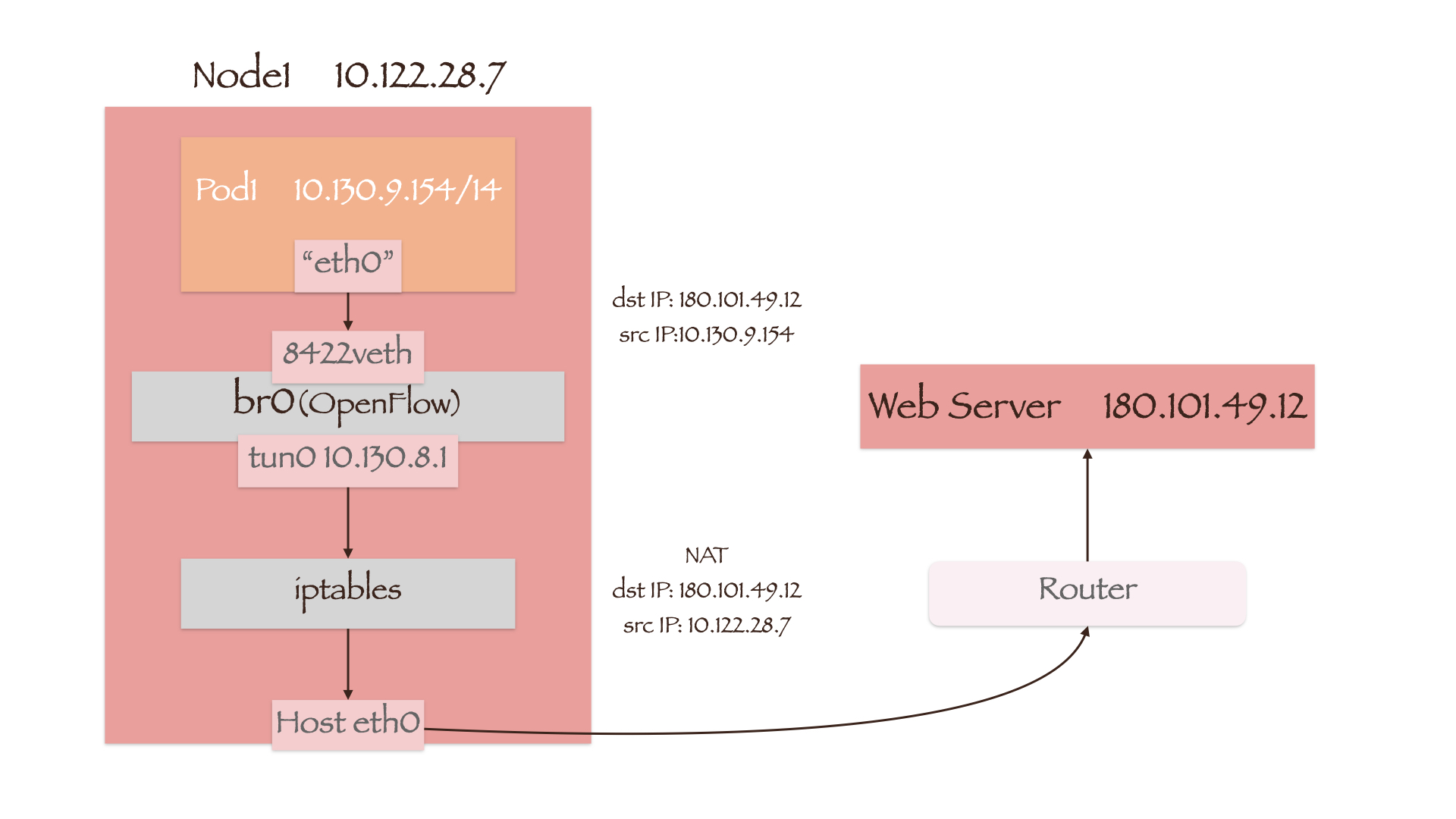
Pod to External
数据包依然首先通过veth-pair送往 OVS 网桥br0,随后便进入了br0上的 OpenFlow 流表:
table=0, n_packets=837268653828, n_bytes=331648403594327, priority=100,ip actions=goto_table:20table=20, n_packets=613807687, n_bytes=220557571042, priority=100,ip,in_port=8422,nw_src=10.130.9.154 actions=load:0->NXM_NX_REG0[],goto_table:21table=21, n_packets=837674296060, n_bytes=331665441915651, priority=0 actions=goto_table:30table=30, n_packets=759636044089, n_bytes=280576476818108, priority=0,ip actions=goto_table:100table=100, n_packets=761732023982, n_bytes=282091648536325, priority=0 actions=output:2
数据包从tun0端口传出后进入节点的路由表及 iptables 处理流:
| |
访问集群外部显然需要通过节点的默认网关,因此数据包将从节点网卡eth0送出。而在POSTROUTING链中,数据包的源地址由 Pod IP 转换为了eth0的 IP 10.122.28.7。完整流程如下图所示(图中的“Router”指的是路由器而非 Openshift 中的概念):
Future Work
- 本文并未涉及 External to Pod 的场景,它是如何实现的?我们都知道 Openshift 是通过 Router(HAProxy)来暴露集群内部服务的,那么数据包在传输过程中的 NAT 操作是怎样进行的?
除了本文提到的几种网络接口外,Openshift 节点上还存在着更新:ovs-system和vxlan_sys_4789。它们的作用是什么?vxlan_sys_4789就是上文提到的端口vxlan0,而ovs-system是一个历史遗留问题,没有任何作用;- Openshift 4.X 版本的网络模型与本文实验用的 3.6 版本相比有那些变化?